Après le livre, l’édition et le numérique, nous plongeons plus profondément dans les rouages des processus d’édition — ou la fabrication d’artefacts éditoriaux — avec la question des formats. Ce chapitre est consacré à la technique éditoriale, considérant que les formats représentent les énonciations, les actes ou les contraintes dont l’édition est l’objet. Comment s’incarne le sens dans une activité d’édition ? Les formats représentent des enjeux épistémologiques qu’il convient d’analyser. Benoît Epron et Marcello Vitali-Rosati pointent à juste titre l’enjeu d’une compréhension et d’une maîtrise des formats dans l’édition :
Les technologies déployées aujourd’hui dans l’édition numérique ont en effet avant tout été développées pour répondre aux besoins de l’informatique d’abord et du Web ensuite. Il s’agit d’un renversement important, puisqu’une part incontournable de l’activité éditoriale devient de fait conditionnée par des choix techniques issus de secteurs d’activité parfois très éloignés de l’édition. Les conséquences de cette situation sont doubles : d’une part, la mise au point et l’adoption des standards techniques du métier ne relèvent plus uniquement d’acteurs du monde de l’édition ; d’autre part, les éditeurs sont contraints de composer avec des formats ou des technologies qui ne correspondent pas nécessairement à leurs enjeux.
Nous avons déjà évoqué la question des formats à plusieurs reprises, mais sans détailler ce que leur origine, leur fonctionnement, leur modélisation ou leur usage impliquent. D’un format à l’autre, l’objectif est de modeler et de convertir des textes pour aboutir à des artefacts. Dans une perspective des études des médias, les formats représentent des enjeux trop importants pour être ignorés, comme le soulignent Axel Volmar, Marek Jancovic et Alexandra Schneider dans l’introduction du recueil Format Matters: Standards, Practices, and Politics in Media Cultures (Jancovic, Volmar & al., 2019, p. 7-22) Jancovic, M., Volmar, A. & Schneider, A. (dir.). (2019). Format Matters Standards, Practices, and Politics in Media Cultures. Meson Press. . Nous n’analysons pas en détail les formats classiques de l’édition, nous nous concentrons plutôt sur les enjeux sémantiques des formats dans une perspective numérique.
Nous définissons tout d’abord ce qu’est un format, autour de sa dimension technique et des notions d’instructions, de formalisation ou de circulation de l’information. Dans un environnement numérique les formats sont la condition d’une interopérabilité via l’établissement de standards. Dans le domaine de l’édition, les formats ont aussi la charge de définir les modalités sémantiques nécessaires à l’édition numérique. Dans un deuxième temps nous décrivons un type de format, le format texte, grâce auquel un balisage sémantique peut être implémenté. Nous dédions une étude de cas à un langage de balisage léger particulier, Markdown, pour comprendre l’essor de pratiques d’édition spécifiques autour des principes du single source publishing. Ces principes sont décrits dans une quatrième section, articulée autour d’une analyse, d’une critique et de perspectives de conceptualisation. Enfin, une étude de cas sur le module d’export de l’éditeur de texte sémantique Stylo vient expliciter la question de l’application des principes du balisage et de la publication multimodale à partir d’une source unique, et plus spécifiquement dans le domaine de l’édition scientifique.
#4.1. Les formats dans l’édition : pour une sémantique omniprésente</>
Commit : 07f3e07
Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-01.md
</>
Commit : 07f3e07Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-01.md
Un format est la condition de circulation d’une information, et plus précisément une série d’instructions déterminées pour qu’une action soit réalisée par un agent. Pourquoi donc s’intéresser aux formats ? Littérature, textes, livres imprimés, fichiers de travail, dimensions des cartons de livres à expédier, livre numérique, conférences de presse, quantité de papier pour l’imprimeur, dans l’édition tout est question de format, la polysémie de ce terme est décidément partout. Formats de fichiers informatiques, mais aussi formats littéraires ou formats de papier, ils peuplent les pratiques d’édition, voire les régissent. Nous l’avons vu en creux dans le chapitre précédentVoir 3.5. Le Novendécaméron ou éditer avec et en numérique, les formats sont une expression de la modélisation des textes.
Ce terme polysémique nécessite un panorama de ce qu’il est entendu par format, avant de définir spécifiquement comment nous qualifions cette notion dans notre étude des processus d’édition (numérique). Parmi toutes les définitions possibles du terme, plusieurs questions sous-jacentes reviennent régulièrement, dont le fait de contrôler, de maîtriser ou de conditionner des pratiques ou des comportements. Les enjeux relatifs aux formes des artefacts ou aux études des médias sont exposés et analysés par la suite. Notre définition exploratoire ne peut exhaustive, tant l’étude des formats devient un champ en soit — le volume Format Matters Standards, Practices, and Politics in Media Cultures publié en 2019 et rassemblant douze contributions le prouve (Jancovic, Volmar & al., 2019) Jancovic, M., Volmar, A. & Schneider, A. (dir.). (2019). Format Matters Standards, Practices, and Politics in Media Cultures. Meson Press. . Nous nous concentrons plus particulièrement sur les formats informatiques et sur la question de la compatibilité entre différents outils utilisés dans les pratiques d’édition. Enfin, au-delà de cette problématique de communication entre logiciels et données, il s’agit d’exprimer au mieux les textes autant pour les humains que pour les machines. Une dimension sémantique est nécessaire à toute pratique d’édition, mais encore faut-il déterminer comment elle se structure et comment elle s’exprime. Si, dans l’édition, tout est format, nous établissons ici que tout est également sémantique.
#4.1.1. Le format : entre formes littéraires, supports matériels et instructions numériques
G. Thomas Tanselle donne quelques exemples de la pluralité des usages linguistiques du terme format, autant dans le monde en général que pour celles et ceux qui étudient les livres, les bibliographes (Tanselle, 2000, p. 68) Tanselle, G. (2000). The Concept of Format. Studies in Bibliography, 53. 67–115. . Notons en préambule que format vient du latin formatus, ce qui signifie formé. Le Dictionnaire de la langue française d’Étienne Littré mentionne même une origine latine tournée vers le livre, liber formatus, « livre de telle ou telle forme » (Littré, 1873, p. 1731) Littré, É. (1873). Dictionnaire de la langue française / Tome 2. L. Hachette. Consulté à l’adresse https://gallica.bnf.fr/ark:/12148/bpt6k5406698m . Le terme est ainsi largement utilisé pour sa dimension technique depuis les débuts de l’imprimerie, pour qualifier les dimensions du papier ou des livres.
Format et édition ont donc beaucoup de points communs, ou tout du moins format et média. Du format littéraire au format informatique, nous explicitons brièvement quelques-unes des acceptions de ce terme en lien avec l’édition et la littérature. Enfin, nous conservons pour le moment un flou entre format de travail ou format d’entrée — input en anglais —, et format de sortie ou résultat — output en anglais —, parce qu’un grand nombre de caractéristiques sont partagées.
Si le terme format est un terme technique, il ne s’agit pas que d’informatique, la technique littéraire est également concernée. Que ce soit des structures définies, des jeux linguistiques ou le soin apporté aux formulations, lorsque nous parlons de formats en littérature nous évoquons la forme des textes. Cette dimension de format peut dériver vers les genres littéraires, dont la classification et le nombre varient selon les époques et les contextesLe même exercice pourrait être effectué pour la musique, où les formats et les genres se croisent aussi.. Poésie, polar, essai, roman ou pamphlet sont des genres mais peuvent aussi être considérés comme des formats dont la structure dépend des contenus. Formes des phrases, découpage en chapitres, longueur totale du texte, matériel critique, autant d’éléments qui modifient aussi la dimension ou l’aspect visuel de l’artefact imprimé — ou numérique. Les formats littéraires — au sens large — coincident parfois ou souvent avec les formats des artefacts, l’objectif étant qu’ils puissent être identifiés facilement par leur forme et leurs dimensions, et de lever ainsi toute ambiguïté sur le contenu d’un objet imprimé. Un livre de poésie peut donc se démarquer d’un pamphlet uniquement par son format, et notamment par la taille ou par la qualité du papier, comme l’explique Meredith L. McGill :
No twenty-first-century reader would have trouble distinguishing a book of poetry from a textbook or a dictionary from a distance of twenty feet.
Un format est une suite d’instructions, et dans le cas d’un support physique comme le livre imprimé cela se traduit principalement par le format de papier. C’est ce que nous avons évoqué plus tôt, l’usage du terme dans un contexte technique débute dès l’émergence de l’imprimerie jusqu’au dix-neuvième siècle où l’usage des presses à imprimer est encore en vigueur. Il s’agit de déterminer quelle est la dimension d’une page d’un livre, celle-ci résultant du pliage puis du découpage d’une plus grande feuille de papier (Genette, 2002, p. 22-23) Genette, G. (2002). Seuils. Éditions du Seuil. . Les formats de papier dépendent alors du nombre de pliages : in-folio pour un seul pliage, soit un feuillet ou quatre pages ; in-quarto pour deux pliages, soit deux feuillets ou huit pages ; in-octavo pour trois pliages, soit quatre feuillets ou seize pages ; etc. C’est ainsi que les bibliographes définissent la notion de format, ce qui pose problème lorsque la zone d’impression ne coincide plus avec la dimension de la page, ou lors de l’apparition du rouleau de papier qui ne nécessite plus de pliage, ou encore lorsque les dimensions de la feuille avant pliage ne sont pas précisées.
The obvious trouble with linking these two examples of “format” [“quarto” and “octavo”] to the basic definition is that a knowledge of paper-folding tells one nothing specific about shape and size unless one knows the shape and size of the paper to start with.
Quoi qu’il en soit ces choix de formats ont plusieurs origines ainsi que de multiples implications. Aux dix-septième et dix-huitième siècles, l’enjeu est d’abord financier, en effet plus une feuille est pliée et moins le budget papier est important. Les dimensions de l’objet imprimé obtenu dépendent en effet du nombre de pliages, et a priori le prix de vente diminue à mesure que le nombre de pliages augmente. Le choix d’un format, toujours pour cette période, n’est pas anodin, comme le résume très bien Meredith L. McGill :
From a publisher’s perspective, format is where economic and technological limitations meet cultural expectations.
Le format concerne donc autant la conception, la production, la diffusion, la circulation ou la réception d’un artefact éditorial. Aujourd’hui, pour l’impression de grands tirages comme c’est le cas avec la technique de l’offset, la question du nombre de pages qui peuvent être disposées sur une feuille se pose encore. Ceci explique par exemple le format « 48CC » en usage dans le domaine de la bande dessinée en Europe depuis le milieu du vingtième siècle (Menu, 2005) Menu, J. (2005). Plates-bandes: janvier 2005 (2e édition). L'Association. , qui correspond à un album de 48 pages (en couleur et avec une couverture cartonnée). Ce format est pensé pour rentabiliser la production de livres à grand tirage dans le secteur de la bande dessinée (Deyzieux, 2008, p. 62) Deyzieux, A. (2008). Les grands courants de la bande dessinée. Le français aujourd'hui, 161(2). 59–68. https://doi.org/10.3917/lfa.161.0059 , chaque objet nécessite trois feuilles au format A1, chacune d’elles formant un feuillet de 16 pages — 16 fois 3 étant égal à 48. Par ailleurs chaque page comporte huit cases, ce qui permet de construire un récit cohérent de 48 fois 8 cases. Le format du support est ici dicté par un désir de bénéfice maximal en imposant une structure de récit.
Toujours dans le domaine de l’impression, mais cette fois avec des machines plus accessibles — les imprimantes dites de bureau —, la question se pose aussi de savoir si tous les formats de papier peuvent être pris en compte. Tout d’abord concernant des tailles très variables, en effet une norme ISO distingue plusieurs dimensions au niveau mondial (Kinross, 2009) Kinross, R. (2009). A4 and Before: Towards a Long History of Paper Sizes. NIAS. , les plus communs A4 et A3 pouvant être pris en charge sur une grande variété d’imprimantes grand public comme professionnelles. Ensuite concernant la compatibilité, notamment avec le cas de l’Amérique du Nord qui n’a pas adopté la norme ISO. L’US Letter est l’équivalent du A4 tout en étant différent (21,6 × 27,9 cm contre 21 × 29,7 cm pour l’A4). Les imprimantes sont capables de prendre en compte ces deux formats. Ce qui semble évident lorsque nous imprimons un document ou que nous feuilletons un livre — donc lorsque nous produisons une information ou lorsque nous y accédons — requiert tout un système dont nous ne prenons pas toujours conscience. Cette circulation de l’information se déroule aussi entre un dispositif informatique et une imprimante, elle ne concerne donc pas que des artefacts imprimés mais aussi des informations numériques, c’est le cas des données permettant à l’imprimante d’inscrire des lettres sur du papier avec de l’encre. Pour communiquer avec l’imprimante il faut un ordinateur compatible. Après les formats littéraires et les formats d’impression, qu’en est-il des formats informatiques ou numériques qui permettent d’éditer aujourd’hui ?
Un format est une suite d’instructions, de « règles », un format informatique structure des informations pour pouvoir être lues et interprétées par une machine et un programme, il s’agit de spécifications techniques. Le format est à distinguer du protocole : le format définit la façon dont les informations sont décrites et stockées, alors que le protocole se réfère à la manière dont une communication est permise entre des formats.
Le numérique, c’est la question des formats.
Un format de document numérique est constitué d’un ensemble de contraintes (ou règles) morphologiques (de forme) et de règles d’interprétation applicables au contenu du fichier (unique) ou des fichiers (multiples) composant un document numérique.
En informatique, donc, un format est la condition d’« interprétation », donc de calculabilité, d’un ensemble de données, ainsi que la garantie d’une communication entre plusieurs dispositifs ou programmes. Pour reprendre le cas de l’impression de bureau, pour qu’un fichier stocké sur un ordinateur puisse être imprimé par une imprimante, encore faut-il que les deux appareils puissent communiquer, et plus précisément que l’imprimante comprenne les instructions données par un logiciel qui est opéré sur l’ordinateur. Un aparté est nécessaire ici : l’origine du logiciel libre vient justement de cette difficulté à transmettre une information depuis un ordinateur vers une imprimante, lors de l’apparition des premiers programmes propriétaires, développés alors par Xerox (Williams, Masutti & al., 2013, p. 2-16) Williams, S., Masutti, C. & Stallman, R. (2013). Richard Stallman et la révolution du logiciel libre: une biographie autorisée (2e éd). Eyrolles. . Nous retrouvons ici les contraintes économiques déjà aperçues avec l’arrivée de l’imprimerie à caractères mobiles : le format est aussi un enjeu de pouvoir. Celle ou celui qui définit les spécifications d’un format maîtrise la circulation de l’information. Dévoiler le fonctionnement d’un format engage donc vers une plus grande connaissance des enjeux liés au numérique, et donc au monde qui nous entoure aujourd’hui. Il nous faut désormais nous attarder sur ces questions de transmission de données dans le domaine numérique.
#4.1.2. Formats, logiciels et compatibilités
Si le processus de l’édition imprimée peut être en partie dévoilé grâce à l’examen des formats (originels ou produits), que nous dit une analyse des formats en informatique ou dans le numérique ? La relation entre formats et logiciels révèle la façon dont ces objets numériques sont construits, mais aussi la manière de les utiliser et les possibilités de leur diffusion ou de leur évolution. Pour expliciter cela nous prenons l’exemple de plusieurs logiciels et de leur format concordant, avant d’aborder la question des standards.
Premier avertissement nécessaire ici, en informatique le format ne doit pas être confondu avec la version, même si une certaine proximité lexicale existe. La distinction est délicate puisque que dans d’autres domaines les deux sont parfois interchangeables : dans l’édition notamment, où un format de livre peut correspondre à une version particulière, le support signifiant ainsi le contenu — comme nous l’avons déjà vu. Mais une version peut aussi correspondre à un changement de format sans pour autant avoir une incidence sur le texte lui-même. En informatique un format définit des spécifications techniques, principalement pour que des données puissent être lisibles par un programme ou bien un logiciel. Une version permet d’identifier l’état d’une donnée, d’un fichier ou d’un programme.
Du point de vue des outils que nous utilisons en environnement numérique — donc les programmes, les logiciels ou les applications — un format est un ensemble de données structurées qui peuvent être traitées.
En informatique tout est une suite de bits — des zéros et des uns en base deux —, mais cette suite peut avoir des sens différents qui sont interprétés grâce au format.
Une image ou un texte sont tous les deux une série de bits, mais l’une est interprétable comme une image, et l’autre comme du texte.
Des algorithmes sont appliqués à ces données via un logiciel, ce dernier doit donc connaître le format pour pouvoir réaliser ces calculs.
C’est ainsi que, bien souvent, un format est attribué à un logiciel, ou un logiciel et son format sont conjointement développés.
Dans le champ de l’édition — pris au sens large —, cela est particulièrement visible avec des logiciels de traitement de texte ou de publication assistée par ordinateur.
Le cas de Microsoft Word est éclairant, tant le format DOC (avec la même extension .doc) est lié à ce logiciel, et inversement.
Microsoft Word est un traitement de texte, il est conçu pour interpréter et éditer — dans le sens de modifier — le format DOC, sans pour autant laisser d’autres logiciels comprendre ce format. À l’inverse, le format DOC est développé pour pouvoir conserver (et transmettre) des informations avec le logiciel Microsoft Word. D’un côté ce logiciel est capable d’enregistrer des données dans d’autres formats (comme le format RTF pour Rich Text Format), mais en perdant un certain niveau de précision (pour ne pas dire fonctionnalités). D’un autre côté, pendant longtemps il était difficile voire impossible d’enregistrer des données au format DOC avec un autre logiciel. Cette absence de compatibilité — un format lisible par différents logiciels — s’explique pour plusieurs raisons. La première révèle une logique fonctionnaliste. Pour s’assurer du meilleur fonctionnement possible du logiciel, la maîtrise du format est nécessaire. Dans le cas de Word et DOC, ce principe est poussé à son paroxysme puisque leur développement est réalisé par Microsoft dans le plus grand secret. Si le format DOC a une spécification technique, elle n’est pas accessible, il n’est donc pas possible de connaître les instructions permettant de structurer les données. Pire, il est interdit de regarder le code source de ce format. Celui-ci étant un format exécutable et non un format texte facilement lisible, un logiciel est forcément nécessaire pour décoder ce qu’il contient. C’est la seconde raison de l’absence de compatibilité, le format et le logiciel sont propriétaires, leur accès n’est permis qu’à certaines conditions très limitées. Tout d’abord leur utilisation nécessite un échange financier, et ensuite pour empêcher une distribution non contrôlée le logiciel est placé sous une licence propriétaire — reconnue légalement.
Jusqu’au développement par Microsoft du format normalisé Office Open XML, le format DOC n’était que très difficilement accessible en dehors de l’environnement de Word.
D’autres logiciels sont parvenus à créer une compatibilité limitée, comme OpenOffice Writer, LibreOffice Writer ou Apple Pages, en tentant de comprendre le fonctionnement de DOC.
Pendant plusieurs années, ce format a été développé sans en révéler ses spécifications, limitant aussi son utilisation en dehors des systèmes d’exploitation compatibles avec Microsoft Word.
Impossible donc d’utiliser Word sur Linux par exemple.
Par ailleurs, il s’agit d’un format binaire, donc une série de bits, contrairement au format .docx, textuel, qui permet une certaine lisibilité.
Cette dépendance développée et entretenue par une entreprise privée n’est pas pour autant inéluctable, des efforts de standardisation ouverte de formats comme ceux utilisés par les traitements de texte sont réalisés pour des raisons idéologiques ou politiques, par exemple permettre à toute personne de pouvoir ouvrir un fichier quel que soit son environnement informatique ; ou pour des raisons économiques, par exemple Microsoft a fait le choix de standardiser son format (via des normes ISO) pour permettre une meilleure compatibilité de lecture et conserver ainsi une forme de monopole — à l’origine basé sur le format, rappelons-le.
La réalisation d’un format standard de traitement de texte compatible entre plusieurs systèmes d’exploitation ou logiciels est une initiative qui a permis d’envisager un monde sans Word, ou tout du moins un monde où Word ne serait plus le seul outil plébiscité, à défaut de se passer de ce type d’outil d’écriture — nous y revenons par la suiteVoir 5.1. Les chaînes d’édition : composer avec les logiciels. Le format OpenDocument a été développé conjointement avec la suite de logiciels LibreOfficeL’histoire de ce logiciel n’est pas développée ici, quoi qu’elle représente un intérêt pour comprendre les jeux de pouvoir entre logiciels open source et libres., proposant notamment un traitement de texte avec LibreOffice Writer. Si certains organismes, comme des administrations en Europe, ont choisi le libre pour des questions d’autonomie et de pérennité (Berne, 2014) Berne, X. (2014). Le ministère du Travail va basculer vers des logiciels de bureautique libres. Consulté à l’adresse https://www.nextinpact.com/article/14311/89239-le-ministere-travail-va-basculer-vers-logiciels-bureautique-libres , Microsoft Word est encore un logiciel qui domine les usages. Le développement d’un standard ouvert ne suffit donc pas à modifier totalement les pratiques, mais ce n’est pas là l’objet de notre étude. Précisons désormais de quoi il s’agit lorsque nous parlons de standard.
#4.1.3. Standards et interopérabilité
Un standard est un ensemble de descriptions techniques formalisées, documentées et partagées, comme nous l’avons vu précédemmentVoir 3.1. Le numérique : culture, politique et ubiquité. L’établissement d’un standard résulte d’une volonté de rendre compréhensible une structuration de données, dans un environnement donné. Cette dernière précision est importante, car le degré d’ouverture d’un standard peut varier. D’une certaine façon, le format DOC est un standard au sein de l’environnement fermé de Microsoft, mais ses spécifications ne sont pas partagées. La normalisation est un autre moyen pour s’accorder sur la détermination d’un format, mais il s’agit alors d’une forme de labellisation donnée par un organisme agréé, qui entraîne souvent des coûts pour qui souhaite connaître les spécifications, participer à l’entreprise de description, ou faire reconnaître une norme. C’est le choix adopté par Microsoft avec le format Office Open XML en 2006. L’enjeu des standards ouverts est de permettre une compatibilité dans différents contextes via la publication d’une documentation et de recommandations, pour enclencher ensuite une potentielle implémentation de cette compatibilité. Cette entreprise de standardisation d’un format révèle les processus politiques de légitimation sous-jacents comme le soulignent Axel Volmar, Marek Jancovic et AlexandraSchneider (Volmar, Jancovic & al., 2019, p. 16) Volmar, A., Jancovic, M. & Schneider, A. (2019). Format Matters: An Introduction to Format Studies. 7–22. https://doi.org/10.25969/mediarep/13663 . Le développement d’un standard ouvert se fait via une communauté en partant des besoins de celle-ci, et c’est là un point déterminant :
Real standards do not suddenly appear. They emerge from one of two processes, informal or formal, during which a proposed standard is recognized as reflecting real needs.
Dans l’environnement numérique que constituent Internet et le Web, l’exemple des Requets for Commentshttps://www.rfc-editor.org illustre ces dimensions de clarification, d’énonciation et de publication déployées pour constituer des standards — en précisant toutefois que les RFCs ne sont pas toutes des standards (Crocker, Huitema & al., 1995) Crocker, S., Huitema, C. & Postel, J. (1995). Not All RFCs are Standards. Internet Engineering Task Force. https://doi.org/10.17487/RFC1796 . Dans un champ connexe — le livre numérique — la standardisation du format EPUB révèle des objectifs divers, tant sur des questions d’accessibilité que sur les enjeux économiques comme nous l’avons exposé dans le chapitre précédentVoir 3.2. Le livre numérique ou la pensée homothétique. Dans un autre domaine, l’encodage de documents dans le champ académique, l’exemple de la TEI (Text Encoding Initiative) offre un aperçu de ce que cela implique. Sans en faire une étude de cas, nous présentons quelques éléments de la constitution du format XML-TEI pour comprendre les motivations nécessaires et le travail fourni permettant d’aboutir à un standard ouvert.
La Text Encoding Initiative est un format de structuration de données mais également une communauté au sein des humanités numériques, dont l’objectif est l’encodage de textes. Le format TEI est plus spécifiquement un schéma XML, créé en 1987 par et pour la communauté scientifique afin de pallier à un manque de ressources pour décrire et publier des ressources textuelles.
Si vous accordez plus d’importance aux mots de votre texte et à leur sens qu’à la façon dont ils sont disposés sur la page, vous rencontrerez bien vite des limites frustrantes en utilisant un traitement de texte classique.
Les besoins des scientifiques qui travaillent sur du texte sont multiples, comme l’identification de la structure d’un document (titres, sous-titres, citations ou numéro de page de l’édition imprimée originale), l’identification de divers éléments comme les personnes, les dates ou les lieux, ou l’intégration de métadonnées riches et structurées. Un outil classique comme un traitement de texte ne peut clairement pas remplir cette mission. La TEI comporte un langage de balisage pour réaliser un travail sémantique dans l’objectif de conserver ces informations ou de pouvoir obtenir un artefact lisible — typiquement un site web avec l’accès à la richesse sémantique du document, ou une édition imprimée pour une transcription graphique. À ce jour la TEI est le seul moyen d’encoder un document de façon sémantique et interopérable. Cette interopérabilité est permise par un important travail de définition du format, qui représente plus de deux mille pages dans sa version imprimable au printemps 2023 (TEI Consortium, 2023) TEI Consortium (2023). TEI P5: Guidelines for Electronic Text Encoding and Interchange. https://doi.org/10.5281/ZENODO.3413524 . Il s’agit de détailler le fonctionnement du schéma — ce que nous ne faisons pas ici — afin de permettre une compréhension autant par des humains que par des programmes. Ces derniers peuvent être développés pour éditer ce format, l’afficher ou le publier. Le parcours de la standardisation est relativement long et fastidieux dans le cas de la TEI, il requiert une structure particulière pour recevoir, traiter voir implémenter des demandes.
<w:body><w:p><w:pPr> <w:pStyle w:val="Titreprincipal"/><w:bidi w:val="0"/><w:spacing w:before="240" w:after="120"/><w:jc w:val="center"/></w:pPr><w:r><w:rPr></w:rPr> <w:t>Titre de mon document</w:t> </w:r></w:p> <w:p><w:pPr><w:pStyle w:val="Corpsdetexte"/><w:bidi w:val="0"/><w:spacing w:lineRule="auto" w:line="276" w:before="0" w:after="140"/><w:jc w:val="left"/><w:rPr></w:rPr></w:pPr><w:r><w:rPr></w:rPr><w:t xml:space="preserve">Texte de description, définissant ce qu’est un </w:t></w:r><w:r><w:rPr><w:rStyle w:val="Concept"/></w:rPr><w:t>livre</w:t></w:r><w:r><w:rPr></w:rPr><w:t>.</w:t></w:r></w:p><w:sectPr><w:type w:val="nextPage"/><w:pgSz w:w="12240" w:h="15840"/><w:pgMar w:left="1134" w:right="1134" w:gutter="0" w:header="0" w:top="1134" w:footer="0" w:bottom="1134"/><w:pgNumType w:fmt="decimal"/><w:formProt w:val="false"/><w:textDirection w:val="lrTb"/></w:sectPr></w:body>
<titre>Titre de mon document</titre> <paragraphe>Texte de description, définissant ce qu'est un <concept identifiant="livre">livre</concept>.</paragraphe>
<title type="main">Titre de mon document</title> <p>Texte de description, définissant ce qu'est un <term xml:id="livre">livre</term>.</p>
L’apport d’un tel standard ouvert est considérable, et concerne principalement les pratiques d’encodage, la formalisation via une méthode de balisage permet en effet à une communauté scientifique de partager des façons de faire. En plus d’être un dispositif de formalisation de pratiques, le développement du standard permet aussi à d’autres acteurs ou structures de développer des applications ou des programmes pour lire et éditer le format XML-TEI (comme oXygen ou LEAF-VRE), pour produire des éditions numériques (avec TEI Publisher) ou pour effectuer des conversions vers d’autres formats de balisage (via XSLT, ou via le convertisseur Pandoc pour la version simplifiée de la TEI)Ce ne sont là que quelques exemples de projets développés à partir du format TEI.. Un dernier point concerne la nécessité de maintenir un standard, en effet cela demande des mises à jour régulières et donc des ressources humaines parfois importantes.
La TEI est un ensemble de bonnes pratiques, constituées d’un format qui inclut lui-même un langage sémantique, ce qui signifie que le sens des différents éléments d’un texte peuvent être annotés afin d’être traités. Le cas de la TEI nous permet d’introduire cette nouvelle notion, en plus de la standardisation, de la compatibilité et de l’interopérabilité, il s’agit donc de décrire le sens avec la sémantique, et d’exprimer cela à travers un format.
#4.1.4. Pour une sémantique du texte
Un format décrit des données pour qu’elles puissent être traitées, cette formalisation est porteuse de sens. C’est ce que nous qualifions ici de sémantique, l’usage de ce terme concerne ici le texte en tant qu’objet (ou source) éditorial ou comme ensemble de données — étant donné la signification distincte de sémantique dans les domaines de la sémiologie ou de la linguistique notamment. Le traitement sémantique d’un texte consiste en l’identification de ses différents éléments, partant du fait qu’un texte n’est pas qu’une suite de mots, de phrases, de paragraphes ou de parties ayant tous la même valeur. Si nous prenons un exemple trivial comme un document qui comporte un titre, un paragraphe et une citation longue, ces trois éléments représentent déjà plusieurs niveaux d’information : un titre est un moyen de nommer un document, voire de le résumer ; un paragraphe est un bloc de texte qui se distingue d’autres blocs de texte ; une citation longue est un bloc de texte particulier qui est rattaché à un auteur ou à une autrice, et qui peut être lié à une référence. Nous distinguons habituellement ces niveaux par un moyen graphique, que ce soit un artefact imprimé ou numérique, par exemple en attribuant une taille de texte plus grande pour le titre ou un alignement sur la page plus important pour la citation. Ainsi nous pouvons repérer visuellement que le premier élément est plus important que le second, et que le troisième est d’une nature distincte. Un format sémantique sépare les données purement textuelles de l’identification que porte chacun des éléments du texte. Sur une page imprimée, un titre, un paragraphe et une citation sont identifiés de façon « superficielle et provisoire plutôt qu’essentielle » comme l’explique les auteurs de « What is Text, Really? » :
The essential parts of any document form what we call “content objects,” and are of many types, such as paragraphs, quotations, emphatic phrases, and attributions. Each type of content object usually has its own appearance when a document is printed or displayed, but that appearance is superficial and transient rather than essential — it is the content elements themselves, along with their content, which form the essence of a document.
Jusqu’ici nous avons utilisé le terme de « texte » pour définir la matière du travail d’édition, et le terme d’artefact pour qualifier le résultat de ce travail. Nous devons désormais utiliser la notion de « document » pour clarifier l’espace où le texte se déploie d’un point de vue sémantique. Un document numérique est l’addition de données et de leur structuration (Pédauque & Melot, 2006) Pédauque, R. & Melot, M. (2006). Le document à la lumière du numérique. C&F éditions. , le format (informatique) est un moyen de contenir les données et d’exprimer cette structure. Plutôt que d’interroger l’intérêt de sémantiser un texte, et donc de recourir à un format sémantique, il s’agit plutôt de considérer que tout texte a forcément une dimension sémantiqueTelle que nous définissons la sémantique.. Même un texte en prose de plusieurs pages dispose d’une structure sémantique, qui peut consister à un seul paragraphe, ou au repérage de chaque phrase, ou à une structuration plus précise comme l’identification d’éléments tels que des personnes, des concepts ou tous les noms communs. Il s’agit ici d’ailleurs d’exemples qui dépassent ce qui est habituellement identifiable avec des moyens graphiques. Faut-il alors tout identifier dans un texte ?
La question de la limite de la sémantisation d’un texte doit prendre en compte les objectifs inhérents au projet. En effet, une fois les principaux éléments d’un document identifiés — tels que les titres et sous-titres, ou les paragraphes —, le niveau de précision peut grandement varier. C’est toute la question que pose une opération d’encodage de manuscrits, faut-il aller jusqu’à désigner chaque saut de ligne ? Est-il pertinent de faire correspondre chaque pronom personnel à une personne physique ? Tout dépend du but final qui peut être de plusieurs natures. Un document sémantique facilite la composition d’un texte en qualifiant les informations qui seront distinguées visuellement dans l’artefact final, et sans ambiguïté pour faciliter un travail collectif. Cela permet également de dissocier la valeur de ces informations de leur mise en forme graphique, en utilisant une feuille de styles appliquée à la structure. Enfin le texte peut être transformé en une base de données, les différents éléments pouvant être extraits et stocker indépendamment les uns des autres, pour ensuite être manipulés dans d’autres contextes d’utilisation. Ces possibilités sont décrites plus précisément dans l’article de Steven J. DeRose, David G. Durand, Elli Mylonas et Allen H. Renear, publié en 1990 (DeRose, Durand & al., 1990) DeRose, S., Durand, D., Mylonas, E. & Renear, A. (1990). What is text, really? Journal of Computing in Higher Education, 1(2). 3–26. https://doi.org/10.1007/BF02941632 , et qui propose une modélisation générique, ouverte et structurante. Dernier point qui vient s’ajouter à cette liste : la conservation sur le long terme des informations sémantiques d’un texte, qu’il soit issu d’une transcription d’un document manuscrit ou imprimé, ou qu’il soit nativement numérique. Quelle que soit la façon dont est exprimée cette sémantique, s’il y a un standard alors il sera toujours possible de décrypter les informations pour une réutilisation. Un texte peut prendre de multiples dimensions, encore faut-il être en mesure de concevoir un format qui stocke et code ces nombreux paramètres.
Le traitement sémantique du texte a une histoire longue à l’échelle de celle de l’informatique, nous nous attardons sur plusieurs formats et leur logiciel pour expliquer l’émergence de cette sémantisation du texte pour l’édition. WordStar, l’un des premiers logiciels de traitement de texte développé pour des environnements DOS en 1978 (donc bien avant les systèmes d’exploitation de Windows ou Apple), comprend un système pour signifier certains détails sémantiques comme l’emphase, qui se traduit par de l’italique ou du gras (Kirschenbaum, 2016, p. 1-9) Kirschenbaum, M. (2016). Track changes: a literary history of word processing. The Belknap Press of Harvard University Press. . Une combinaison de touches permet d’identifier des caractéristiques sémantiques d’éléments du texte, tout cela étant stocké dans un fichier texte — sur lequel nous revenons plus tardVoir 4.2. Les conditions de la sémantique : format texte et balisage) —, l’interface de WordStar se rapprochant plus d’un terminal que d’un environnement graphique comme les logiciels développés à partir de la fin des années 1980.
Autre exemple de tentative de sémantisation, la même année, avec le format TeX que nous avons déjà présentéVoir 3.3. Éditer avec le numérique : le cas d’Ekdosis. Un système de commandes identifie des portions de texte ou des éléments de structure, d’abord dans une finalité de composition graphique, mais cette dernière traduit malgré tout une volonté de donner du sens au texte. Comme nous l’avons vu, les choses se compliquent avec le format DOC, fermé, mais qui pose un autre problème : les informations sémantiques sont mêlées avec celles concernant la mise en forme. L’objectif principal du logiciel Microsoft Word est de rédiger des documents pour les imprimer, voir pour les conserver au format DOC ou éventuellement au format PDF — ce dernier figeant la mise en forme mais empêchant toute édition. Word applique le modèle de la page imprimée, à tel point que l’interface n’invite pas à réfléchir à la structure d’un document autrement que par son rendu graphique final. GML survient dans ce contexte d’édition de documents destinés à être imprimés, et repose sur une logique de balises — qui donnera naissance à XML puis HTML. Le format devient SGML pour séparer strictement sens du texte et mise en forme, et introduit ainsi la question du marquage des documents.
Étudier la notion de « format » nous invite à questionner les enjeux de compatibilité, d’interopérabilité ou de standard, voici comment nous le conceptualisons :
Définition Format
Liste des conceptsUn format définit la façon dont des informations sont décrites et stockées, il s’agit d’une série d’instructions formalisées afin qu’une action soit réalisée par un agent. L’établissement d’un format est la condition de circulation d’une information, son choix révèle donc une intention mais aussi un acte. Dans l’édition, le format définit les caractéristiques techniques de la modélisation du texte, de sa structure et de la façon dont ses artefacts peuvent être produits. Il peut faire l’objet d’un standard afin d’être partagé et de permettre une interopérabilité voire une modularité. Définir un format n’est pas une action neutre, et participe à l’acte éditorial dans son ensemble.
Ces dimensions nous permettent d’aborder des formats spécifiques qui sont une façon d’appliquer la sémantique, les formats de balisage.
#4.2. Les conditions de la sémantique : format texte et balisage</>
Commit : 8053125
Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-02.md
</>
Commit : 8053125Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-02.md
Le format est une notion qui invoque nombre d’enjeux épistémologiques dans le domaine de l’édition, dont certains ont été abordés avec la description de ce terme dans la section précédenteVoir 4.1. Les formats dans l’édition : pour une sémantique omniprésente — en lien avec les questions de logiciel et de standard —, il est désormais temps d’analyser la condition de l’implémentation d’une dimension sémantique dans le texte.
Faire de la sémantique dans un texte, en vue de produire des artefacts éditoriaux divers, est possible à condition de déterminer un format spécifique qui répond à plusieurs contraintes. Ces dernières sont d’ordres théoriques et pratiques, et notamment sur les questions de prise en compte des besoins et du contexte, de l’inscription de la démarche dans une approche précise, et des résultats attendus. La direction prise vers des formats texte de balisage, décrits dans cette section, répond à la nécessité de comprendre et de maîtriser les processus d’édition, et de rendre la chaîne d’édition interopérable voire modulaire. Un autre impératif est à prendre en compte : la conservation des sources des documents pour un traitement ultérieur et notamment avec des outils et des processus différents que ceux initiaux. Ici nous n’abordons pas d’autres formats en usage dans le champ de l’édition, dont ceux utilisés par des logiciels de traitement de texte ou de publication assistée par ordinateur, propriétaires ou libres, tout simplement parce qu’ils ne permettent pas d’envisager la constitution d’une chaîne d’édition numérique — comme nous l’avons présenté dans le chapitre précédentVoir 3.2. Le livre numérique ou la pensée homothétique. Nous considérons que le format texte et les langages de balisage permettent d’utiliser le numérique en envisageant de nouvelles modalités éditoriales, plutôt qu’en dupliquant le schème de l’imprimé. La constitution d’une sémantique compréhensible, lisible et néanmoins puissante permet la maîtrise de la composition du sens, inhérente à toute activité d’édition. Choisir, délimiter ou créer un format sémantique est aussi une étape dans la construction de chaînes d’édition. Il s’agit ainsi d’adapter ou de développer des protocoles plutôt que d’adopter des dictats.
Notre argumentaire sur les conditions de la sémantique, qui s’inscrit pleinement dans l’étude des formats dans l’édition, se divise en quatre temps. Tout d’abord la description du type de format qui permet d’accueillir des balisages divers, le format texte. Il s’agit ensuite de comprendre comment intégrer, dans le format texte, des possibilités de sémantisation des textes, en définissant précisément le terme balisage. Nous établissons une typologie du ou des balisages, afin de relever les enjeux épistémologiques profonds de tels formats. Enfin, si nous avons déjà donné quelques éléments concernant les formats de balisage en abordant l’histoire des formats sémantiques, nous décrivons plusieurs moments clés du développement de langages de balisage majeurs comme SGML, TEI, HTML ou XML.
#4.2.1. Définition du format texte
Le format texte est un format de fichier informatique qui ne comporte que des caractères textuels. Le format texte est lisible par des logiciels qui affichent uniquement ces caractères ou qui les interprètent pour exécuter des actions.
MINORITIES VERSUS MAJORITIES If I were to give a summary of the tendency of our times, I would say, Quantity. The multitude, the mass spirit, dominates everywhere, destroying quality. Our entire life--production, politics, and education--rests on quantity, on numbers. The worker who once took pride in the thoroughness and quality of his work, has been replaced by brainless, incompetent automatons, who turn out enormous quantities of things, valueless to themselves, and generally injurious to the rest of mankind. Thus quantity, instead of adding to life's comforts and peace, has merely increased man's burden.
Comme nous pouvons le voir dans cet extrait, le format texte ne contient rien d’autres que des caractères typographiques, seules les majuscules permettent d’identifier un fragment différent du document, en l’occurrence un titre. Le format texte peut révéler ses éléments de structuration, voire sa sémantique, autant pour les humains que pour les machines, par le biais d’un langage, ce langage pouvant être interprété par un logiciel. Le format texte est un format qui comporte des instructions univoques.
Plain text identifies a file format and a frame of mind.
L’introduction de Plain Text de Dennis Tenen apporte une double dimension technique et épistémologique, indiquant que le choix de ce type de format n’est pas qu’un besoin technologique, il s’agit aussi d’adopter un certain rapport au numérique et au texte. Comme nous le voyons par la suite, utiliser le format texte peut requérir quelques compétences qui sont liées au format lui-même — et en particulier au langage sémantique — et non au logiciel habituellement associé. Cette littératie est également une perspective enthousiasmante, puisqu’elle donne plus de maîtrise et de liberté aux personnes qui l’acquièrent. D’un point de vue plus pratique, voici une définition du format texte extraite du manuel de présentation et de documentation d’Unicode :
Plain text is a pure sequence of character codes; plain Unicode-encoded text is a sequence of Unicode character codes. In contrast, fancy text, also known as rich text, is any text representation consisting of plain text plus added information such as language identifier, font size, color, hypertext links, and so on. For example, the text of this book, a multifont text as formatted by a desktop publishing system, is fancy text.
Pourquoi s’arrêter sur cette définition qui distingue un format simple ou brut et un format riche ? Tout d’abord parce que The Unicode Consortium est un groupement chargé de définir comment chaque signe est encodé pour que chaque système numérique puisse l’afficher. Cette initiative est destinée à rendre tout texte compatible, quelle que soit sa langue, afin d’afficher sur n’importe quel dispositif informatique des symboles ou des glyphes tels que les caractères de l’alphabet latin (en prenant en compte la casse ou les diacritiques), les marques de ponctuation en usage dans certaines langues, les kanji japonais, ou encore l’alphabet arabe — pour ne prendre que quelques exemples. The Unicode Consortium est donc bien placé pour définir ce qu’est le format texte. Ensuite, cette définition apporte une distinction importante entre deux formats : le premier, le plain text, est une suite de caractères sans mise en forme, il s’agit du contenu ; le second, le fancy text ou rich text, est l’addition du plain text et d’informations complémentaires indiquant notamment le format, la mise en forme, des liens hypertextes, etc. Nous retenons cette distinction seulement pour marquer la différence entre un format qui contient les contenus (ou le texte et sa structuration sémantique) et un format qui contient également des éléments de mise en forme (ou le rendu graphique selon le type d’artefact qui est produit). Nous rejoignons cette définition qui indique en creux que le format texte ne contiendrait que le texte, au sens du texte définit dans « What is Text, Really? » (DeRose, Durand & al., 1990) DeRose, S., Durand, D., Mylonas, E. & Renear, A. (1990). What is text, really? Journal of Computing in Higher Education, 1(2). 3–26. https://doi.org/10.1007/BF02941632 , donc des contenus et leur qualification sémantique mais sans l’attribution d’une équivalence graphique. Nous critiquons toutefois l’emploi du terme « pur », notre position rejoignant celle d’Arthur Perret (Perret, 2022, p. 154) Perret, A. (2022). De l’héritage épistémologique de Paul Otlet à une théorie relationnelle de l’organisation des connaissances. Thèse de doctorat, Université Bordeaux Montaigne. Consulté à l’adresse https://these.arthurperret.fr , ce terme apportant de la confusion sur la possible simplicité d’un tel format, et cela implique un jugement par rapport au type de données, notamment la différence avec certains formats qui doivent être interprétés voire exécutés pour être lus ou édités.
Le format texte est lisible et exécutable, c’est ici l’un des points d’achoppement que nous souhaitons souligner. Ce format peut être à la fois affiché tel quel, ou exécuté par une machine qui déclenche des actions en fonction des caractères qui y sont inscrits. Cette double compréhension, par les humains et les machines, ouvre plusieurs perspectives, comme l’interopérabilité et le choix des modes d’édition. En étant par défaut ouvert, et révélant autant ses contenus que ses instructions, le format texte peut offrir plus facilement des possibilités d’interopérabilité. En effet, tout fichier au format texte peut être modifié avec n’importe quel éditeur de texte, le format étant décorrélé du logiciel. Cela signifie aussi que le fichier peut potentiellement rester lisible dans un temps très long. Ce format ne doit pas nécessairement être édité avec un éditeur de texte, d’autres logiciels permettent d’afficher ses contenus voir d’interpréter sa syntaxe (s’il y en a une) afin de faciliter sa compréhension. C’est le cas du format XML-TEI par exemple, qui peut être lu avec éditeur de texte simple qui n’affiche que les caractères, ou un éditeur de texte plus avancé qui interprète le balisage et affiche une coloration syntaxique pour distinguer les différentes balises, ou encore un logiciel qui accompagne l’écriture (comme l’enchaînement autorisé des balises). Ces différents modes d’édition interviennent à différents moments d’un travail d’édition ou dépendent du profil des personnes qui réalisent ce travail. Arthur Perret signale d’autres apports conséquents de ce format comme la stabilité, la fiabilité, le stoïcisme ou la textualité :
Et alors, considérez la question suivante : pour tous ces gestes qui passent par le texte, est-ce qu’il vous serait utile de connaître une technique universelle simple, légère, performante, portable, gratuite, pérenne, pouvant rendre toutes sortes de services ? Une sorte de lingua franca, de plus petit dénominateur commun de la textualité version numérique ? Songez à la versatilité du couple papier-crayon pour toutes les tâches d’écriture ; transposez-la à l’informatique : vous obtenez le format texte.
Ces bénéfices conduisent à un autre argument de poids qui explique son adhésion dans le domaine informatique : les états d’un fichier au format texte peuvent être gérés avec des systèmes de gestion de versions tels que Git. Ce versionnement, difficile avec des encodages riches, est possible avec ce type de format. En effet, les différences entre deux états d’un fichier au format texte peuvent être visualisées très facilement : un caractère a par exemple été supprimé à telle ligne du fichier, et trois autres ont été ajoutées à une autre ligne. Le format texte est ainsi un format qui représente des avantages certains dans un contexte numérique, tout en nécessitant des phases de conversion ou de transformation pour aboutir à un artefact — c’est ce que nous détaillons par la suiteVoir 4.4. Le single source publishing comme acte éditorial sémantique. Avant d’expliciter comment il est possible d’appliquer une sémantique avec ou dans le format texte, nous explorons ses origines.
#4.2.2. Origines et distinctions du format texte
D’où vient le format texte ? Il s’agit d’un des formats les plus utilisés, puisqu’il est très largement employé dans l’informatique comme la source privilégiée des programmes ou des logiciels. Chaque programme étant ainsi composé d’un certain nombre de fichiers au format texte, et plus spécifiquement dans des langages de programmation eux-mêmes représentés par une série de caractères. Le format texte est donc partoutDe nombreux langages de programmation ne sont toutefois pas basés sur le format texte, Smalltalk est un exemple parmi beaucoup d’autres., et ce depuis les débuts de l’informatique. Comme nous l’avons dit précédemment, son usage s’explique en raison de sa grande simplicité et de son interopérabilité inhérente. C’est donc un moyen efficace, durable et compatible de stocker des informations, sans parler du fait que les fichiers dans ce format sont — potentiellement — très légers. Pour comprendre tout cela, il est possible d’aller ouvrir les fichiers source d’un programme ou d’un logiciel avec un éditeur de texte, la plupart du temps ils consistent en une série de lettres, de chiffres et de symboles typographiques compréhensibles — principalement dans des langues occidentales. Dans la grande majorité des cas ces fichiers sont donc au format texte, et lisibles directement dans un éditeur de texte.
Plusieurs contextes nécessitent de recourir à des formats exécutables qui ne sont lisibles que dans des environnements très spécifiques. Le stockage de données relationnelles, par exemple, est facilement réalisé dans des formats qui ne sont pas qu’une suite de caractères. C’est le cas du format de base de données SQLPour Structured Query Language ou Langage de requête structurée en français. où l’information est organisée dans des tableaux, à deux dimensions, liés entre eux. Nous pouvons observer un constat similaire dans le développement de certains programmes qui sont enregistrés dans un format image, notamment pour des raisons de performance. Ces cas révèlent des besoins en termes d’environnement de travail, il s’agit d’accéder à des données complexes directement depuis un fichier plutôt que par le biais de multiples fichiers au format texte avec des syntaxes diverses. Un fichier exécutable par un système d’exploitation est, selon les objectifs visés, parfois plus pertinent qu’un format texte. Un exemple parmi d’autres est la façon dont l’éditeur de texte Vim gère les données : le fichier texte est enregistré à chaque fois que la commande enregistrer est appelée, mais dès qu’une lettre est tapée Vim stocke temporairement ces données dans le buffer, qui n’est pas un fichier au format texte. C’est le format SWP (pour swap ou échange en français) qui est utilisé pour cet usage. Son encodage n’est pas au format texte, son ouverture avec un éditeur de texte révèle ainsi une suite de caractères incompréhensibles, que seul logiciel Vim peut interpréter. Si des formats de base de données ont toutefois adoptés le format texte, et si Vim enregistre les données finales dans un fichier au format texte, il est intéressant de noter pourquoi ce n’est pas le type de format qui pourrait remplacer tous les autres. Il y a toutefois une tendance, depuis quelques années, à se tourner vers des formats texte pour l’écriture ou l’édition, et pour expliquer ce phénomène nous pouvons reprendre l’exemple des traitements de texte en général et du format DOC et de Microsoft Word en particulier.
Word, et son format DOC, a dominé les usages dans le champ des traitements de texte pendant plusieurs années.
Nous l’avons déjà signaléVoir 4.1. Les formats dans l’édition : pour une sémantique omniprésente, le format DOC est dit binaire ou exécutable, il ne comporte donc pas qu’une série de caractères typographiques — en l’occurrence il s’agit de scripts, d’informations de mise en forme, etc.
Impossible de lire un fichier .doc avec autre chose que WordD’autres logiciels étaient et sont capables de lire ce format, parfois avec des pertes d’information., comme un éditeur de texte.
Le choix d’adopter un standard ouvert et normalisé, Office Open XML, permet une certaine compatibilité.
Le format DOCX est une implémentation de ce standard, qui encapsule un certain nombre de fichiers texte — à la façon du format EPUB —, permettant en théorie à plusieurs programmes d’y accéder.
L’ouverture logicielle ne suffit pas, tant il est compliqué de comprendre l’encodage verbeux du schéma XML utilisé.
Pour des opérations simples tel qu’un texte structuré de façon très sommaire, ce format implique une forte opacité comme nous pouvons le voir ci-dessous.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <w:document xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" mc:Ignorable="w14 wp14 w15"> <w:body><w:p><w:pPr><w:pStyle w:val="Normal"/><w:bidi w:val="0"/><w:jc w:val="left"/><w:rPr></w:rPr></w:pPr><w:r><w:rPr></w:rPr> <w:t>Bonjour</w:t> </w:r></w:p><w:sectPr><w:type w:val="nextPage"/><w:pgSz w:w="12240" w:h="15840"/><w:pgMar w:left="1134" w:right="1134" w:gutter="0" w:header="0" w:top="1134" w:footer="0" w:bottom="1134"/><w:pgNumType w:fmt="decimal"/><w:formProt w:val="false"/><w:textDirection w:val="lrTb"/></w:sectPr></w:body></w:document>
Dans les quelques lignes de XML ci-dessus nous découvrons le mot « Bonjour », perdu dans un ensemble de données qui définissent autant le format que la façon dont ces sept lettres doivent être disposées sur la page — les informations concernant le rendu graphique sont stockées dans un autre fichier. L’hégémonie des formats DOC ou DOCX est pourtant remise en cause avec l’apparition de logiciels plus simples, dédiés à l’écriture et moins aux tâches bureaucratiques, comme le signale Matthew Kirschenbaum dans Track Changes, son enquête sur les traitements de texte (Kirschenbaum, 2016, p. 235-247) Kirschenbaum, M. (2016). Track changes: a literary history of word processing. The Belknap Press of Harvard University Press. . L’usage d’applications en ligne telles que Google Docs vient notamment remettre en cause ce monopole. Aussi, des solutions alternatives apparaissent au début des années 2010, loin des logiciels monopolistiques ou des applications de géants du numérique, avec cette volonté, dans certains domaines, de prendre soin du texte et des personnes qui interviennent dessus (Maxwell, 2022) Maxwell, J. (2022). The Care-ful Reviewer: Peer Review as if People Mattered. Pop! Public. Open. Participatory(4). https://doi.org/10.54590/pop.2022.004 . C’est le cas du logiciel iA Writer au début des années 2010, uniquement dédié à l’écriture plutôt qu’à la création de documents bureautiques. iA Writer utilise justement un format texte — en l’occurrence Markdown, que nous présentons longuement dans l’étude de cas qui suitVoir 4.3. Le langage de balisage léger Markdown : entre interopérabilité et compromis —, format qui peut être utilisé avec de nombreux autres logiciels. Il s’agit d’une forme de retour au format texte, avec l’apparition d’un nouveau type d’application qui permet de l’éditer, sans pour autant enfermer des utilisateurs dans des formats propriétaires ou limités à certains logiciels. Dans le cas de Markdown et du logiciel iA Writer, le format et le texte lui-même ne font plus qu’un, pour reprendre les mots d’Oliver Reichenstein (l’un des créateurs de iA) :
In Plain Text the text is the source. With Rich Text we see a simulation. What we see may please us, but below the surface our word processor secretly builds a more complex text in code.
iA Writer est un exemple intéressant, parce qu’il est entièrement conçu autour d’un format texte, pour en développer des fonctionnalités indépendantes. Dit autrement, ici le logiciel n’influence pas les spécifications du format, mais il est construit autour de lui. Le concept de developer experience, entendu comme un ensemble de processus et d’outils simples et efficients basés sur des standards plutôt que sur des interfaces et des fonctionnalités complexes (Fagerholm & Münch, 2012) Fagerholm, F. & Münch, J. (2012). Developer experience: Concept and definition. https://doi.org/10.1109/ICSSP.2012.6225984 , a surement influencé le développement de iA Writer. Notons que de nombreux logiciels d’écriture basés sur le format texte Markdown existent aux côtés d’iA Writer, et qu’il s’agit là d’usages difficiles à quantifier, mais toujours minoritaires par rapport aux traitements de texte classiques — et plus précisément Microsoft Word.
Le format texte, dans le cas de l’édition — prise au sens très large —, implique une transformation pour obtenir divers artefacts, des formats dits de sortie. Les traitements de texte sont des machines à tout faire, et intègrent des fonctions d’export — notamment en PDF — quand leur format ne devient pas une finalité en soi. Le format texte implique ainsi de découpler les étapes d’édition, le format texte concernant d’abord l’écriture — l’inscription et la fixation de données.
Nous avons donné quelques clés de compréhension concernant les origines du format texte et son usage dans les domaines de l’informatique ou de l’édition. Ce que nous n’avons pas encore dit, c’est la manière dont les informations contenues dans un format texte peuvent être inscrites, ou comment faire de la sémantique dans un environnement où tout est (d)écrit avec des caractères.
#4.2.3. Du format texte à la sémantique
Le format texte amène à considérer une épistémologie de la connaissance tournée vers l’autonomie et l’ouverture. Encore faut-il disposer d’un moyen pour y exprimer des niveaux de sémantique, sans quoi l’intérêt de ce type de format est très limité. Une des étymologies grecques du terme « sémantique » est notamment σῆμα, soit « signe, marque ». Dans notre cas la question de sémantiser un texte revient à y apposer des marques, afin d’identifier différents niveaux d’information ou de valeurs textuelles. Ces marques doivent être compréhensibles par des personnes humaines, mais aussi par des programmes informatiques qui les interprètent. Le premier enjeu ici est donc de déterminer une syntaxe pour réaliser ce double objectif, la difficulté résidant dans les contraintes du format texte — une suite de caractères — et dans les éventuelles ambiguïtés ainsi générées — il s’agit en effet de définir des éléments textuels qui ne sont pas des mots, qui sont des paratextes. Les symboles typographiques utilisés pour marquer le texte, que ce soit des lettres, des marques de ponctuation ou tous autres signes disponibles dans la grande variété des glyphes, doivent être lisibles par des humains ou des machines. L’objectif est donc d’abord de signifier des valeurs plutôt que d’attribuer un rendu graphique pour les différents éléments d’un texte ; car tout texte est marqué, révélant des choix typographiques ou un agencement graphique particulier du texte sur la page ou sur l’écran.
All text is marked text, as you may see by reflecting on the very text you are now reading. As you follow this conceptual exposition, watch the physical embodiments that shape the ideas and the process of thought. Do you see the typeface, do you recognize it? Does it mean anything to you, and if not, why not?
Comme le dit Jerome McGann ci-dessus, les incarnations physiques qui nous permettent de comprendre le sens sont en soi implicites, mais toujours présentes et sous différentes formes. Toutefois des considérations uniquement visuelles ne prennent pas en compte une attribution déclarative du sens qui dépasse un environnement graphique, environnement dans lequel l’interprétation ne peut être calculée de façon univoque. C’est une pratique courante des traitements de texte avec le mode WYSIWYG. Ce mode What You See Is What You Get — ce que vous voyez est ce que vous obtenez, en français — consiste à appliquer une mise en forme pour distinguer par exemple un titre (dans une police de plus grande taille) du texte principal (dans une police de plus petite taille), ou d’autres éléments comme un texte en emphase (par exemple en italique) ou une liste non ordonnée (par exemple avec un retrait et un tiret devant chaque entrée de cette liste) ; mais cette mise en forme n’a pas toujours une valeur sémantique. L’héritage de l’imprimé, avec ce rendu visuel omniprésent et la logique de la page, est remis en cause dans un environnement où tout peut être calculé. Nous l’avons vu précédemmentVoir 4.1. Les formats dans l’édition : pour une sémantique omniprésente, des moyens ont été mis en œuvre dès les années 1960 pour déclarer une sémantique calculable et sans ambiguïté, via le format texte ; que ce soit avec GML en 1969, puis TeX en 1978 et SGML en 1986 (Blanc & Haute, 2018) Blanc, J. & Haute, L. (2018). Technologies de l’édition numérique. Sciences du design, 8(2). 11–17. https://doi.org/10.3917/sdd.008.0011 . C’est la fonction du balisage que de donner du sens au texte dans le format texte, pour pouvoir être traité dans un environnement numérique. Le balisage est ainsi le compagnon du format texte.
Qu’est-ce que le balisage ? Une balise est un point de repère, un élément qui peut être facilement identifié pour fixer une limite. En dehors du champ du livre il s’agit de placer une signalisation en bois sur la route, sur la mer ou autour de rails, afin de circuler. Pour le texte l’enjeu est très similaire, c’est notre regard qui doit être guidé pour comprendre quelle valeur est attribuée à des portions de lettres, de mots ou de phrases, comme nous pouvons le voir avec l’exemple ci-dessous balisé dans le format AsciiDoc :
Les _balises_ sont des éléments typographiques, textuellement graphiques, qui permettent d'identifier le *sens*.
L’usage de ce terme pour des noms d’initiatives scientifiques va dans ce sens : la revue française Balisages se situe « ainsi à l’intersection des sciences de l’information et de la communication, de l’histoire du livre et des bibliothèques, et de l’anthropologie des savoirs » ; ou la conférence annuelle du même nom (au singulier), « Balisage », qui se définit comme « where serious markup practitioners and theoreticians meet every summer ». L’équivalent de « balisage » en langue anglaise est markup, contraction de mark et up, et est issu non pas d’objets en bois, mais d’une pratique d’annotation des manuscrits pour faciliter le travail des imprimeurs. Baliser ou marquer est alors une pratique qui consiste à ajouter des indications pour que la composition typographique soit au plus proche des intentions de l’éditeur, il s’agit d’une formalisation destinée à donner une autre dimension au texte. À ce titre ce travail d’annotation est probablement plus constitutif de l’acte d’édition que les intentions parfois ambigües d’un éditeur. Cette origine étymologique nous permet de noter le saut effectué entre un modèle imprimé, où les informations ont d’abord une valeur pour la composition graphique, vers un modèle numérique, où l’importance devient le sens qui se traduit ensuite en une forme par un calcul ou une computation. Nous passons d’instructions pour un rendu graphique à l’adoption de règles de traitement pour attribuer du sens. Du WYSIWYG nous allons vers le WYSIWYM — pour What You See Is What You Mean ce que vous voyez est ce que vous signifiez, en français.
All texts are marked texts, i.e., algorithms— coded sets of reading instructions.
Pour reprendre Jerome McGann, tout texte comporte des instructions de lecture, encore faut-il que ces instructions soient univoques, et autant pour des personnes qui vont voir ou déchiffrer ces informations, ou pour des machines qui vont les interpréter caractère par caractère. Ainsi si nous établissons une distinction stricte entre des informations de composition et l’application d’une sémantique, tout texte demeure un texte balisé. La principale différence réside dans les valeurs qui sont données à des fragments de texte et à la manière de les attribuer dans le format texte, de façon lisible et sans ambiguïté. Le format texte est le candidat idéal pour exprimer une sémantique de manière intelligible, manifeste et transparente.
Définition Format de balisage
Liste des conceptsUn format de balisage est une série d’instructions pour modéliser une information et plus particulièrement un texte. Ces instructions doivent être univoques, afin d’être compréhensibles par des personnes qui les lisent ou les machines qui les traitent. Tout fragment de texte peut ainsi être balisé pour déclarer le sens qu’il porte, marquant une distinction entre des données textuelles telles qu’une citation, un paragraphe ou même une date. Les balises sont des points de repères, permettant de naviguer dans un texte et de construire des modélisations épistémologiques.
En même temps qu’explorer certaines des façons de faire qui sont adoptées pour appliquer une sémantique dans cet environnement contraint, il est nécessaire d’établir une typologie des balisages, puis d’analyser quelques-unes de leurs limites.
#4.2.4. Histoire et typologie
Comme nous l’avons exprimé en creux précédemment, il y a plusieurs façons de baliser un texte qui ne sont pas tant des implémentations techniques que le reflet d’un positionnement par rapport au texte pour des applications déterminées — encodage, composition, production simultanée de plusieurs artefacts, archivage, etc. Il peut s’agir par exemple de composer un texte pour obtenir un rendu graphique, ou conserver toutes les informations liées à la structuration sémantique du document pour un archivage. Adopter un type de balisage résulte d’une approche heuristique, qui consiste à définir une manière de signifier. Pour comprendre les enjeux liés au balisage nous devons d’abord comprendre son émergence dans des buts différents, révélant ainsi une typologie riche, puis explorer les types de choix techniques existants.
Tout d’abord, que faut-il baliser ? Il faut prendre en compte plusieurs niveaux dans un texte, quel que soit le balisage. Nous établissons ici un rapide panorama qui ne se veut pas exhaustif, et principalement axé autour de documents de type livre, dans le champ des lettres. Une distinction entre deux niveaux du texte est nécessaire ici. Chaque mot ou suite de mots peut être identifié, c’est le cas de l’attribution de l’emphase à un ou plusieurs termes pour marquer leur importance, et qui peut se traduire par une mise en forme en italique. Cette suite de caractères, souvent définie comme un élément en ligne — inline-level content en anglais —, ou élément de texte, dans les descriptions de balisages comme SGML ou HTML, peut s’étendre d’un caractère à plusieurs phrases. Cette délimitation ne dépasse pas la ligne comme son nom l’indique, la limite étant le paragraphe. Ce dernier est le second niveau, défini comme un élément de bloc ou bloc de texte — block-level content en anglais. Cette unité peut concerner des données comme une suite de mots qui forment un ensemble distinct sémantiquement et graphiquement d’une autre série de mots, une zone qui dépasse la ligne, comme un paragraphe, une figure et sa légende, ou encore un titre — la diversité des éléments de bloc est grande. Enfin, il s’agit de décrire le document lui-même, et c’est là une distinction plus délicate avec la notion de métadonnées. Voilà une des limites du balisage, puisque dans certains cas cette description méta d’un document est déléguée à un autre type de format, le format de sérialisation de données — nous décrivons plus longuement cette distinction dans l’étude de cas qui suitVoir 4.3. Le langage de balisage léger Markdown : entre interopérabilité et compromis.
L’histoire du balisage est longue à l’échelle de l’informatique, et est principalement liée à des besoins industriels de production et de gestion de documents, ou à des contraintes de diffusion scientifique. Ainsi les cas d’expérimentation, notamment dans des domaines non marchands, artistiques ou littéraires, sont minoritaires. La typologie qui suit est basée sur les travaux de James H. Coombs, Allen H. Renear et Steven J. DeRose (Coombs, Renear & al., 1987) Coombs, J., Renear, A. & DeRose, S. (1987). Markup systems and the future of scholarly text processing. Communications of the ACM, 30(11). 933–947. https://doi.org/10.1145/32206.32209 qui restent pertinents sur plusieurs aspects même après plus de trente ans.

Si nous considérons une typologie progressive partant d’une syntaxe avec peu de paramètres et allant vers une plus grande précision sémantique, le format texte est d’abord utilisé sans balisage. C’est le cas avec le premier livre numérique diffusé par Michael Hart et qui donne lieu au projet Gutenberg, comme nous l’avons vu précédemmentVoir 3.2. Le livre numérique ou la pensée homothétique. Il s’agit, d’une certaine façon, d’un texte sans distinction apparente — autre que des sauts de ligne et l’usage éventuel des majuscules. Nous considérons qu’il s’agit ici soit d’une absence totale de balisage, soit d’un balisage dit présentationnel dans le cas de l’usage d’une composition typographique quelle qu’elle soit. D’une certaine façon, les traitements de texte utilisent une forme de balisage présentationnel, en faisant un usage massif d’un rendu graphique y compris pour le texte en cours d’écriture. Le terme de markup en anglais — que nous traduisons par balisage et vice versa — provient d’une pratique d’annotation pour la préparation de documents à imprimer. Il s’agit d’un balisage procédural qui consiste à décrire le comportement du texte dans une perspective de rendu graphique, et donc à décomposer l’écriture de l’édition. Cette pratique, largement répandue pendant toute une période, ne porte pas d’informations sémantiques, à moins de faire une correspondance par exemple entre un retrait d’un bloc de texte et le fait qu’il s’agisse d’une citation longue. La seule manière d’exprimer une information sémantique sur un support imprimé est l’utilisation d’un langage graphique : une taille de police plus grande pour un titre, et beaucoup plus petite pour une note. Par ailleurs, le balisage procédural considère le texte comme un flux, et non comme un ensemble de données, ce qui engendre des instructions qui ne valent que dans une lecture linéaire du document. GML (Generalized Markup Language) est le point d’articulation entre un balisage procédural et un balisage descriptif, et plus spécifiquement une tentative de formaliser des instructions autant pour les humains que pour les machines. GML — ou plus exactement IBM GML puisqu’il s’agit d’une initiative de l’entreprise informatique IBMNotons que IBM est également impliquée dans ce qui peut souvent être considérée comme la naissance des humanités numériques avec le projet Index Thomesticus de Roberto Busa. — est créé en 1969 pour remplacer le système de composition PostScript. Le but de GML est la composition de documents en vue de les imprimer, en séparant le contenu de son format.
The Generalized Markup Language (GML) is a language for document description. It can be used to describe the structure and text elements (parts) of a document without regard to the processing that may be required to format them.
Le principe de distinction entre les informations qui concernent le contenu d’un document, sa dimension sémantique et son équivalence graphique, est à l’origine de GML et des langages de balisage qui suivront. Dit autrement, il s’agit de séparer le contenu de sa présentation, ou encore de rendre le contenu indépendant de son format, comme le décrit Charles F. Goldfarb, l’un des créateurs de GML puis de SGML :
Many credit the start of the generic coding movement to a presentation made by William Tunnicliffe, chairman of the Graphic Communications Association (GCA) Composition Committee, during a meeting at the Canadian Government Printing Office in September 1967: his topic – the separation of information content of documents from their format.
Avec GML le rendu graphique est toujours l’objectif final, via son implémentation dans le système DCF (Document Composition Facility) d’IBM.
Les indications se font beaucoup plus précises pour lever toute ambiguïté grâce à l’utilisation de macros, héritées de pratiques de programmation — une macro est une suite de caractères indiquant une fonction comprise par un programme ou un logiciel.
Notons qu’au même moment Brian Reid crée le langage de balisage Scribe (accompagné d’un compilateur),qui comporte une séparation stricte entre le contenu et sa présentation
(Reid,
1980)
Reid,
B.
(1980).
Scribe: A Document Specification Language and Its Compiler.
Thèse de doctorat,
ProQuest Dissertations Publishing.
.
À la suite de GML émerge un second balisage en 1986, descriptif cette fois, avec SGML (Standard Generalized Markup Language)
(Goldfarb & Rubinsky,
1990)
Goldfarb,
C. & Rubinsky,
Y.
(1990).
The SGML Handbook.
Clarendon Press.
.
SGML considère un document comme un ensemble de données, chacune pouvant être identifiée via l’utilisation de balises englobantes.
Chaque portion — en bloc ou en ligne — qui nécessite des indications sémantiques est encadrée par des balises ouvrantes et fermantes indiquées avec des chevrons, comme <quote>ceci</quote>.
Entre la création de GML puis de SGML, d’autres tentatives sont développées pour baliser du texte, comme le format TeX puis le système de composition qui l’accompagne LaTeXVoir 3.3. Éditer avec le numérique : le cas d’Ekdosis.
Donald Knuth crée TeX afin d’obtenir des documents mis en forme avec une forte exigence typographique.
Il s’agit ici d’un balisage à la fois procédural et descriptif, des macros permettant autant d’indiquer ponctuellement des actions nécessaires pour la composition de document ou attribuant une valeur en englobant des portions de texte.
En 1987 émerge un autre format de balisage descriptif, TEI, destiné à encoder et non à composer des documents. Nous avons déjà présenté ce formatVoir 4.1. Les formats dans l’édition : pour une sémantique omniprésente, pensé comme un moyen de définir en premier lieu le sens d’un texte, et plus spécifiquement dans une activité d’encodage de documents initialement imprimés. Notons que la TEI est créée quelques années avant des formats plus populaires comme XML ou HTML. La TEI est d’abord une application de SGML, avant de devenir un schéma XML.
Le format HTML est développé à partir de 1990, également comme une application de SGML, Tim Berners-Lee s’inspire de ces principes en créant une série de balises utiles à l’affichage de documents dans un navigateur web, mais dont le rendu graphique n’est pas la seule finalité. Dès les débuts du Web, l’objectif est d’en permettre un usage très large, y compris à des personnes en situation de handicap. Le sens donné au texte est donc autant destiné à être interprété puis affiché par un navigateur web, qu’à être transcrit dans diverses formes pour des personnes ne pouvant voir le rendu graphique. La distinction forte entre HTML et XML peut être explicitée avec les formats XHTML et HTML5 : le premier est un schéma XML, dont l’usage ne peut qu’être rigoureux, qui est censé permettre l’utilisation de puissants outils liés à XML dans des environnements web ; le second est une évolution du langage HTML avec la dimension permissive qui le définit. La déconnexion entre XML et HTML intervient à un moment où la communauté qui travaille avec ces formats est plus tournée vers les outils du Web et moins vers des usages académiques. Cette déconnexion révèle aussi des limites intrinsèques à tout balisage, et le type de modélisation épistémologique qui vient avec. Nous analysons quelques-uns des rapports avec le sens qui jalonnent la création de syntaxes.
#4.2.5. Les limites du balisage
Les différentes initiatives de balisage du texte, qui débutent avec ce principe fort d’une séparation de la structure d’un document et de sa représentation graphique, sont sujettes à des limites qu’il faut mentionner. Elles ne représentent pas un barrage en soi, mais constituent un certain nombre de contraintes inhérentes à toute implémentation technique de principes théoriques. Plus encore, ces limites révèlent des questionnements épistémologiques précieux pour notre recherche, que nous étudions sous trois angles. Il s’agit tout d’abord de la question des types de balisage, chacun hérité de divers domaines comme l’informatique, manifestant un rapport au texte et aux artefacts qui peuvent en être produits. Le deuxième angle concerne des enjeux sémantiques complexes quand il s’agit de baliser des éléments qui se chevauchent, problème largement abordé notamment par la communauté TEI. Enfin, la troisième approche concerne le degré d’adoption des balisages et les tentatives de détournement de certains d’entre eux. L’intérêt ici est d’explorer des limites théoriques et pratiques qui remettent en perspective cette recherche d’une précision sémantique détachée des impératifs du modèle imprimé. Toute la difficulté réside ici dans la perspective d’une mise en calcul du texte, en appliquant des algorithmes à des marques typographiques.
Il n’y a pas un mais des balisages, de GML jusqu’à XML en passant par TeX ou HTML, et sans mentionner des balisages dits légers qui sont abordés dans l’étude de cas qui suitVoir 4.3. Le langage de balisage léger Markdown : entre interopérabilité et compromis. Si jusqu’ici nous n’avons principalement parlé que de balisage, il est plus juste d’utiliser le terme de langage pour qualifier l’usage de caractères typographiques pour marquer la sémantique des documents au format texte. Ces langages de balisage font appel à différents types de mécanismes pour identifier des portions de textes et leur attribuer une valeur — sémantique. Pour expliciter cela nous montrons la différence entre les macros de TeX et les balises de HTML, pour signifier sémantiquement la même chose, et dans l’objectif de produire un artefact avec rendu graphique, comme dans l’exemple ci-dessous — rendu graphique, balisage au format TeX, et balisage au format HTML :

\title{Les fabriques d'édition : un double mouvement éditorial} \author{Antoine Fauchié} \begin{document} \maketitle Les technologies de l'édition, et plus particulièrement de l'édition numérique, ont beaucoup évolué depuis le début des années 2000, avec l'apparition de chaînes de publication qui s'éloignent peu à peu des outils classiques d'édition. Fabriquer une publication, et plus spécifiquement un livre, est une opportunité pour certaines structures de construire leurs propres outils d'édition et de publication. Nous présentons plusieurs initiatives d'édition, basées sur ce que nous nommons des \emph{fabriques d'édition}, afin d'observer et d'analyser ces nouvelles façons de faire, d'éditer, comme un nouveau mouvement éditorial.
<title>Les fabriques d'édition : un double mouvement éditorial</title> <meta name="author" content="Antoine Fauchié"> </head> <body> <h1>Les fabriques d'édition : un double mouvement éditorial</h1> <p>Les technologies de l'édition, et plus particulièrement de l'édition numérique, ont beaucoup évolué depuis le début des années 2000, avec l'apparition de chaînes de publication qui s'éloignent peu à peu des outils classiques d'édition. Fabriquer une publication, et plus spécifiquement un livre, est une opportunité pour certaines structures de construire leurs propres outils d'édition et de publication. Nous présentons plusieurs initiatives d'édition, basées sur ce que nous nommons des <em>fabriques d'édition</em>, afin d'observer et d'analyser ces nouvelles façons de faire, d'éditer, comme un nouveau mouvement éditorial.</p>
Un texte balisé avec LaTeX fait appel à des macros ou à des commandes, permettant de déclarer les caractéristiques d’une portion de texte ou d’exécuter une action.
Si une macro comme \emph{ceci est un texte en emphase} est très similaire à une balise comme <em>ceci est un texte en emphase</em> — le texte concerné est balisé avant et après, et la balise dispose d’un identifiant clair —, en revanche la commande \maketitle est un fonctionnement inconnu pour le langage HTML qui ne dispose pas d’un système de publication intégré — puisque c’est le navigateur qui se charge d’interpréter les informations.
En revanche la dimension sémantique de HTML est plus forte que TeX, l’élément <title> permettant de spécifier le titre du document et l’élément <h1> permettant de déclarer le titre principal de la page — quand bien même cette page ne correspond plus à son équivalent syntaxique imprimé.
Dans les deux cas il manque une modélisation du texte, nécessaire au-delà du balisage pour prévoir justement où va se situer le titre du document et comment l’exprimer — graphiquement ou sémantiquement —, et c’est précisément ce que nous nous proposons d’explorer par la suiteVoir 4.4. Le single source publishing comme acte éditorial sémantique avec le concept d’acte éditorial sémantique.
Les choix de balisage portent donc des modélisations et des manières de faire.
Autre limite liée au balisage, le problème récurrent et très documenté qui concerne une question liée aux principes de SGML, et ses applications comme HTML ou XML : le chevauchement.
En effet les balises ne peuvent pas se chevaucher, en HTML il est par exemple impossible d’écrire <em>mot <strong>très</em> important</strong>.
Une solution possible serait <em>mot <strong>très</strong></em> <strong>important</strong>, soit une façon plus verbeuse d’exprimer une structure similaire.
Des cas sont bien plus complexes, lorsqu’il s’agit notamment de baliser des citations qui passent d’un paragraphe à un autre, comme le signale de façon détaillée Steven DeRose
(DeRose,
2004)
DeRose,
S.
(2004).
Markup Overlap: A Review and a Horse.
.
En SGML une solution a été trouvée, CONCUR, pourtant impossible à transposer dans des langages comme XML ou HTML, pour des raisons d’interprétation :
<(DTD1)p>And the Lord said, <(DTD2)q>Read my lips: Do not murder.</(DTD1)p> <(DTD1)p>Be nice to each other instead.</(DTD2)q> And the people said "Amen."</(DTD1)p>
Un langage a même été développé pour répondre à ce type de besoin, TAGML (pour Text as Graph Markup Language)
(Bleeker, Buitendijk
& al.,
2020)
Bleeker,
E., Buitendijk,
B. & Dekker,
R.
(2020).
Between Flexibility and Universality: Combining TAGML and XML to Enhance the Modeling of Cultural Heritage Text. Dans Karsdorp,
F.,
McGillivray,
B.,
Nerghes,
A. & Wevers,
M. (dir.),
Proceedings of the Workshop on Computational Humanities Research (CHR 2020). (pp. 340–350).
CEUR.
, basé sur un système de balises et de suffixes : [s|L1>Ceci est un [del|L2>exemple<del] illustratif.<s].
Des expérimentations ont aussi été menées pour transposer ce type de marquage dans XML ou XML-TEI.
TeX, en tant que langage de balisage, accompagné de LaTeX et d’un paquet spécifique, combinant également ces différentes approches comme nous pouvons le voir dans cet exemple où le balisage de portions de texte destinées à la création d’un index chevauche celui des paragraphes :
\section{Markdown} \index{markdown|(} Le format Markdown est un format de balisage léger, dont la syntaxe est réduite à quelques signes typographiques. \section{La syntaxe de Markdown} \begin{quote} Thus, Markdown. Email-style writing for the web. \end{quote} \index{markdown|)}
Ces questions de chevauchement semblent anecdotiques, elles révèlent pourtant la complexité d’une formalisation claire et sans ambiguïté, et les multiples tentatives de réduire ces problèmes dans des environnements variés — SGML ou TEI pour le balisage sémantique et TeX/LaTeX qui est plus spécifiquement tourné vers la composition graphique.
Une autre limite aperçue précédemment est le degré de compréhension des langages de balisage, qui conduit à la création d’autres manières de marquer le texte. HTML, LaTeX ou TEI sont des langages complexes, même sans la question de la gestion délicate du chevauchement. Ils requièrent une connaissance des éléments, balises ou macros et de leur fonctionnement entre eux. Ce sont aussi des systèmes de balisage verbeux, les éléments qui les composent pouvant être nombreux — parfois augmentés par des attributs —, ce qui implique beaucoup de bruit autour du texte initialSi tant est qu’il y ait un texte initial.. Cette complexité est parfois réduite grâce à des logiciels spécialisés — typiquement oXygen pour XML ou XML-TEI —, facilitant la saisie des éléments ou proposant une vue sans les balises afin d’accéder à un rendu graphique. Il est ainsi possible de dissimuler des éléments syntaxiques pour faciliter leur saisie via un mode « auteur ». Ce type de solution pose plusieurs questions, et notamment celle de la maîtrise du langage sémantique. En disparaissant, les moyens mis en œuvre pour marquer le texte deviennent confus, et c’est la capacité même d’écrire le texte quel qu’il soit qui est remise en cause. Si nous pouvons nous accorder sur le fait que la connaissance des centaines de balises de la TEI est impossible, il est en revanche envisageable de considérer des étapes de balisage préalables plus simples, plus légères. Et donc d’adopter d’autres langages pour traiter des sources, sans pour autant délaisser la richesse des langages issus notamment de SGML. Ces initiatives, qui relèvent d’une forme de détournement, sont les langages de balisage dits légers que nous analysons dans l’étude de cas qui suit. Ils présentent un fort intérêt pour l’usage du balisage sémantique dans l’édition, remettant en cause les modèles puissants mais néanmoins contraignants tels que TeX, TEI ou même HTML. L’idée ici est de disposer d’instructions claires et univoques, mais aussi plus restreintes et utilisables dans des environnements très divers. L’enjeu est également de réduire les moyens nécessaires à une pratique d’écriture ou d’édition sémantique.
#4.3. Le langage de balisage léger Markdown : entre interopérabilité et compromis</>
Commit : 07f3e07
Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-03.md
</>
Commit : 07f3e07Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-03.md
Cette étude de cas a pour objectif d’illustrer le concept de format dans le contexte de l’édition, et ainsi d’analyser comment les enjeux sémantiques se manifestent dans un format spécifique. Nous avons souligné l’intérêt de l’analyse des formats dans la perspective d’une étude de l’édition (numérique) ; le format est une suite d’instructions permettant une modélisation du sens. Pour concevoir cette modélisation, la syntaxe sémantique ne doit pas être occultée, elle doit être visible et compréhensible : le mode WYSIWYG des outils d’écriture et d’édition empêche d’avoir accès à la dimension sémantique d’un document ; et masquer la syntaxe dans un mode auteur, dans le cas de langages de balisage complexes, ne permet pas non plus une maîtrise de cette modélisation. Comment exprimer une sémantique dans un environnement textuel modélisable et compréhensible ? L’analyse du format Markdown, langage de balisage léger largement adopté dans de multiples domaines d’édition ou de gestion de documents, permet d’envisager des pratiques d’édition numérique où les processus sont conçus conjointement aux opérations sur les textes.
Les projets éditoriaux qui adoptent le langage de balisage léger Markdown sont nombreux, ses usages et ses implémentations dans des chaînes d’édition sont divers et reflètent des actes éditoriaux multiples. Que révèle le format Markdown dans les pratiques d’édition avec le format texte, et dans la constitution de fabriques d’édition ? Nous nous plaçons toujours dans une perspective d’ouverture des techniques d’édition, et nous débutons cette étude de cas par un panorama historique, en explicitant l’apparition de ce type de langage de balisage et sa filiation avec des systèmes sémiotiques antérieurs. Les influences qui ont conduit à la création du format Markdown puis à son adhésion sont nombreuses. Son succès s’explique en partie par la simplicité de sa syntaxe, décrite dans un deuxième temps. Cette description est néanmoins une tâche complexe, tant les versions ou saveurs de Markdown sont nombreuses, créées notamment pour augmenter la sémantique originelle ; elles reflètent des choix techniques et épistémologiques. C’est ce que nous présentons dans un troisième temps en explicitant pourquoi Markdown ne dispose pas d’un standard. Enfin il s’agit d’aborder l’enjeu de la conversion, ou comment transformer ce format de travail vers des formats de sortie qui donneront lieu à des artefacts. Le convertisseur Pandoc, l’un des plus plébiscités pour ces opérations de conversion, est historiquement et structurellement très fortement lié à Markdown. Dans ce contexte de format texte, Pandoc explicite le principe de modélisation éditoriale dans l’acte d’édition par l’articulation entre des actions comme parser et écrire, via une représentation abstraite de cette modélisation. Pandoc formalise nombre d’enjeux techniques autour de cette idée qui paraît pourtant simple : comment faire de la sémantique à partir de quelques signes typographiques ? Si le format texte peut se révéler une solution universelle pour l’édition, un travail important est nécessaire pour l’élaboration de processus qui l’intègrent.
#4.3.1. Aux origines des langages de balisage léger
Qu’est-ce qui a présidé à l’émergence des langages de balisage léger dans un contexte d’édition ou de publication numérique ? Avant de détailler l’histoire et le fonctionnement de Markdown, ainsi que ses implications épistémologiques, nous explorons le contexte d’apparition des langages de balisage léger et les besoins initiaux qui ont contribué à leur création. Les différentes initiatives convergent vers une volonté de rendre visible l’acte sémantique. Ainsi, s’intéresser aux langages de balisage léger revient à « être attentif au milieu de l’écriture » comme l’expriment Serge Bouchardon et Isabelle Cailleau :
Être attentif au milieu de l’écriture, c’est comprendre qu’il n’y a pas de milieu technique qui ne soit aussi un milieu social (une communauté de savoirs et de pouvoirs).
Dans cette perspective, il y a un fort enjeu à tenter de rendre « visible » et « lisible » notre milieu numérique dans ses différents aspects : théoriques (propriétés spécifiques du numérique), techniques (fonctions qui les matérialisent dans des outils d’écriture et de lecture) et sémiotiques (pratiques sociales incarnées).
Les langages de balisage léger participent ainsi à une entreprise de dévoilement des initiatives de sémantisation. Ils répondent à un double objectif : permettre de réaliser des opérations d’écriture sémantique — numérique — conviviales (Illich, 2014) Illich, I. (2014). La convivialité. Éditions Points. , et générer des instructions afin de permettre aux machines de calculer la structure du texte. Setext, créé en 1992, est une réponse pratique à ce double enjeu. Il s’agit d’un des premiers langages de balisage léger pour écrire et diffuser des documents via Internet. L’idée est relativement simple : utiliser des caractères ASCIIL’American Standard Code for Information Interchange, ou Code américain normalisé pour l’échange d’information, est une norme de codage de caractères désormais remplacée par Unicode. pour donner toutes les indications relatives à la structuration d’un texte, tout en étant lisible facilement — c’est-à-dire sans besoin d’effectuer la tâche complexe d’analyser la structure sémantique de cette source, comme c’est le cas avec les langages de balisage hérités de SGML comme HTML. Setext est un format lisible et interopérable : des programmes peuvent lire ce format et en donner une représentation graphique ; néanmoins si aucun programme n’est capable d’interpréter ce langage, il est compréhensible par des personnes humaines. Setext signifie « structure-enhanced text » (Engst, 1992) Engst, A. (1992). TidBITS in new format. Consulté à l’adresse https://tidbits.com/1992/01/06/tidbits-in-new-format/ : un format texte qui dispose d’une structuration.
Titre du document ================= Paragraphe quelconque avec **un texte en emphase (gras)** ainsi qu'un autre ~fragment en emphase (italique)~.
Comme nous pouvons le voir dans l’exemple ci-dessus, il s’agit d’une sémiotique qui sert la sémantique.
Les éléments signifiant consistent en un ou plusieurs caractères typographiques accessibles via tout clavier — occidental — des années 1990.
À la place des balises présentées précédemmentVoir 4.2. Les conditions de la sémantique : format texte et balisage, du type <em>englobante</em>, qui ne sont pas créées pour être lues et qui sont ainsi jugées verbeuses pour qui les parcourt, ce ne sont que quelques signes qui indiquent la valeur sémantique de tel ou tel fragment de texte.
Le changement de paradigme est fort, puisque d’un langage pour les machines — typiquement SGML et ses applications — nous passons à un langage pour les humains et pour les programmes informatiques.
À la suite de cette initiative, plusieurs langages sont créés pour des besoins divers, se plaçant chacun dans des contextes spécifiques. Nous observons alors un phénomène d’éclatement, puisque plusieurs d’entre eux réalisent des opérations parfois très similaires. La filiation avec Setext n’est par ailleurs pas toujours avouée, pourtant les grammaires se ressemblent beaucoup. Nous pouvons noter l’omniprésence de l’astérisque, dont l’héritage vient des comics américains comme le signale Matthew Gay (Guay, 2020) Guay, M. (2020). The story behind Markdown. Consulté à l’adresse https://capiche.com/e/markdown-history commenté par Arthur Perret (Perret, 2020) Perret, A. (2020). Histoire typographique de la légèreté. Consulté à l’adresse https://www.arthurperret.fr/histoire-typographique-legerete.html . D’autres caractères typographiques reviennent fréquemment, inspirés par la programmation ou parce qu’il s’agit des caractères disponibles facilement, et qui n’introduisent pas d’ambiguïté dans la lecture.
Que ce soit atx — créé par Aaron Swartz en 2002 pour écrire des courriels — ou Textile — créé par Dean Allen aussi en 2002 pour faciliter l’écriture dans le CMS Textpattern — les similitudes sont nombreuses et oscillent entre un format trop simple avec le premier, et un balisage déjà complexe avec le second. Textile propose en effet de nombreux marqueurs pour indiquer des informations sémantiques avancées mais aussi des instructions de composition — comme l’alignement du texte.
h2. Textile p=.Features: * is a _shorthand syntax_ used to generate valid HTML * is *easy* to read and *easy* to write * can generate complex pages, including: headings, quotes, lists, tables and figures Textile integrations are available for "a wide range of platforms":/article/.
<h2>Textile</h2> <p style="text-align:center;">Features:</p> <ul> <li>is a <em>shorthand syntax</em> used to generate valid <span class="caps">HTML</span></li> <li>is <strong>easy</strong> to read and <strong>easy</strong> to write</li> <li>can generate complex pages, including: headings, quotes, lists, tables and figures</li> </ul> <p>Textile integrations are available for <a href="/article/">a wide range of platforms</a>.</p>
Textile se positionne comme le moyen d’écrire du balisage HTML sans écrire de code HTML. Le CMS Textpattern se charge de la conversion depuis Textile vers HTML, mais ce format est aussi utilisé dans d’autres environnements, et ainsi d’autres parseurs sont développés. Ces derniers appliquent une série de règles établies en fonction des spécifications du format, les règles peuvent toutefois varier d’un programme à l’autre et générer des ambiguïtés.
Markdown apparaît dans ce contexte où un balisage sémantique simple est recherché, pour écrire puis publier des documents dans un environnement numérique. Textile répond à cet objectif, mais avec des options trop nombreuses. C’est pourquoi John Gruber conçoit le langage de balisage Markdown en s’inspirant de Textile et de atx, cherchant ainsi un compromis pour la publication de pages web. Il crée le format — donc ses spécifications — et un programme pour convertir des fichiers Markdown vers le format HTML, avec l’aide d’Aaron SwartzAaron Swartz était un militant et informaticien qui a notamment contribué à la mise en place d’un certain nombre de standards et à différents combats autour du droit d’auteur ou de l’accès à l’information.. John Gruber explique de façon très explicite son intention :
A Markdown-formatted document should be publishable as-is, as plain text, without looking like it’s been marked up with tags or formatting instructions. While Markdown’s syntax has been influenced by several existing text-to-HTML filters — including Setext, atx, Textile, reStructuredText, Grutatext, and EtText — the single biggest source of inspiration for Markdown’s syntax is the format of plain text email.
To this end, Markdown’s syntax is comprised entirely of punctuation characters, which punctuation characters have been carefully chosen so as to look like what they mean.
Il s’agit d’écrire des pages HTML sans devoir en utiliser les balises, ainsi que d’étendre cette pratique numérique à une écriture lisible en toute situation, qu’il y ait conversion du format ou non. Si l’influence de la conception de ce langage est en partie celle de la programmation, et donc des syntaxes qui y sont habituellement employées, Markdown se détache du système de balises héritées de SGML. À partir de quelques marqueurs signifiés avec des caractères typographiques simples et non ambigus, en l’occurrence uniquement des signes de ponctuation, ce langage permet d’écrire facilement des documents structurés en HTML — jusqu’à une certaine limite, nous y reviendrons. Comme l’explique Robin de Mourat, l’enjeu est en partie esthétique :
Le format Markdown implique un rapport paradoxal à la forme et à la « présentation » des textes, puisqu’il dénote un souci esthétique important pour la pratique de l’écriture – il est voulu élégant à lire et facile à écrire – tout en déléguant à d’autres dispositifs techniques les questions de mise en forme pour la lecture des écrits par le public.
Rappelons-le avec force, le but premier de cette syntaxe est d’être convertie, mais sa lecture est aussi possible sans opération(s) intermédiaire(s). C’est l’une des trois clés du succès comme l’exprime également Sean Leonard :
Since its introduction in 2004, Markdown has enjoyed remarkable success. Markdown works for users for three key reasons. First, the markup instructions (in text) look similar to the markup that they represent; therefore, the cognitive burden to learn the syntax is low.
L’apprentissage et la maîtrise de ce langage de balisage léger sont en effet rapides, les différentes balises nécessaires pour structurer un document sont faciles à mémoriser. Les deux autres raisons exprimées par Sean Leonard sont d’ordre technique et d’usage. Tout d’abord, les éléments syntaxiques sont déterminés par l’outil de conversion du format Markdown vers un autre format, ce point est prolongé à la fin de cette étude de cas. Ensuite, une importante communauté hétérogène s’est saisie du format, en adaptant, modifiant et étendant ce langage. Le fonctionnement de Markdown mérite que nous nous attardions plus longuement sur ses mécanismes sémantiques.
#4.3.2. Les principes de la syntaxe Markdown
Markdown place le sens au centre de l’écriture, dans un environnement que nous pouvons qualifier de convivial pour reprendre un terme de Ivan Illich (Illich, 2014) Illich, I. (2014). La convivialité. Éditions Points. . Cela se traduit par une simplicité et une certaine élégance dans l’opération de sémantisation, mais aussi une appropriation du format dans ses multiples saveurs avec les convertisseurs qui les accompagnent. La syntaxe du langage de balisage léger Markdown est une série de spécifications techniques, cette syntaxe repose sur une série de signes typographiques et sur une opération de conversion pour obtenir une page HTML. Cette syntaxe constitue aussi un nouveau rapport au texte, à la fois l’implémentation d’un moyen simple d’appliquer une sémantique, et la promesse d’obtenir un format diffusable et interopérable.
When you write and read text that’s marked-up with HTML tags, it’s forcing you to concentrate on the think of it. It’s the feel of it that I want Markdown-formatted text to convey.
La notion de sensation est relativement floue ici. Nous l’interprétons comme l’implémentation spécifique d’une écriture avec le format texte, où la maîtrise de la grammaire sémantique est suffisamment simple pour permettre une certaine fluidité de la rédaction. Nous détaillons cela en analysant la syntaxe nécessaire à la rédaction d’un texte simple, en présentant les trois versions successives d’un même contenu : la source au format Markdown, le même contenu converti au format HTML, et le rendu graphique correspondant — dans ce dernier cas la feuille de styles qui est appliquée est celle par défaut du navigateur web Firefox.
# Les fabriques d'édition : un double mouvement éditorial Antoine Fauchié Les technologies de l'édition, et plus particulièrement de l'édition numérique, ont beaucoup évolué depuis le début des années 2000, avec l'apparition de chaînes de publication qui s'éloignent peu à peu des outils classiques d'édition. Fabriquer une publication, et plus spécifiquement un livre, est une opportunité pour certaines structures de construire leurs propres outils d'édition et de publication. Nous présentons plusieurs initiatives d'édition, basées sur ce que nous nommons des *fabriques d'édition*, afin d'observer et d'analyser ces nouvelles façons de faire, d'éditer, comme un nouveau mouvement éditorial. ## Définition de l'édition L'édition est entendue comme un processus constitué de trois fonctions : - la fonction **de choix et de production** ; - la fonction **de légitimation** ; - la fonction **de diffusion**. > L’édition peut être comprise comme un processus de médiation qui permet à un contenu d’exister et d’être accessible. On peut distinguer trois étapes de ce processus qui correspondent à trois fonctions différentes de l’édition : une fonction de choix et de production, une fonction de légitimation et une fonction de diffusion. > [Source : Benoît Epron et Marcello Vitali-Rosati, _L'édition à l'ère numérique_](https://papyrus.bib.umontreal.ca/xmlui/handle/1866/20642)
<h1>Les fabriques d’édition : un double mouvement éditorial</h1> <p>Antoine Fauchié</p> <p>Les technologies de l’édition, et plus particulièrement de l’édition numérique, ont beaucoup évolué depuis le début des années 2000, avec l’apparition de chaînes de publication qui s’éloignent peu à peu des outils classiques d’édition. Fabriquer une publication, et plus spécifiquement un livre, est une opportunité pour certaines structures de construire leurs propres outils d’édition et de publication. Nous présentons plusieurs initiatives d’édition, basées sur ce que nous nommons des <em>fabriques d’édition</em>, afin d’observer et d’analyser ces nouvelles façons de faire, d’éditer, comme un nouveau mouvement éditorial.</p> <h2>Définition de l’édition</h2> <p>L’édition est entendue comme un processus constitué de trois fonctions :</p> <ul> <li>la fonction <strong>de choix et de production</strong> ;</li> <li>la fonction <strong>de légitimation</strong> ;</li> <li>la fonction <strong>de diffusion</strong>.</li> </ul> <blockquote> <p>L’édition peut être comprise comme un processus de médiation qui permet à un contenu d’exister et d’être accessible. On peut distinguer trois étapes de ce processus qui correspondent à trois fonctions différentes de l’édition : une fonction de choix et de production, une fonction de légitimation et une fonction de diffusion.<br /> <a href="https://papyrus.bib.umontreal.ca/xmlui/handle/1866/20642">Source : Benoît Epron et Marcello Vitali-Rosati, <em>L’édition à l’ère numérique</em></a></p> </blockquote>

Avant de détailler les exemples ci-dessus nous devons rappeler une distinction fondamentale entre deux niveaux sémantiques d’un texte : les éléments de bloc et les éléments de texte, tels que présentés dans la section précédenteVoir 4.2. Les conditions de la sémantique : format texte et balisage, et ce pour chacune des syntaxes qui suivent.
Les signes typographiques utilisés pour baliser le texte sont donc les suivants : le saut de paragraphe (saut de ligne suivi d’un second saut de ligne) pour indiquer le début puis la fin d’un paragraphe (élément de bloc) ; des croisillons (ou carrés), #, autant que nécessaire et suivi d’un espace pour indiquer les niveaux de titre croissants jusqu’à six (élément de bloc) ; un ou deux astérisques englobant une suite caractères, *, sans espace le suivant et le précédant, pour signifier un texte en emphase (un astérisque) ou qualifié de fort (deux astérisques) (élément de texte dans les deux cas) ; un chevron (fermant), >, suivi d’un espace pour signaler une citation longue (élément de bloc) ; une suite de tirets, -, suivi d’un espace pour représenter une liste non ordonnée (élément de bloc) ; des crochets, [], englobant une suite de caractères sans espace après et avant, suivi de parenthèses, (), englobant une seconde suite de caractères, et qualifiant respectivement un texte considéré comme un lien hypertexte et la cible du lien en question (élément de texte) ; etc.
La documentation initiale complète ces quelques éléments, auxquels il faut ajouter la liste ordonnée, l’insertion d’une image, le saut de ligne, le code, ainsi que des variantes ou des fonctionnements spécifiques pour tous ces types de balisage
(Gruber,
2004)
Gruber,
J.
(2004).
Markdown Syntax Documentation.
Consulté à l’adresse
https://daringfireball.net/projects/markdown/syntax#philosophy
.
La simplicité du langage — il s’agissait initialement de pouvoir baliser dix éléments sémantiques distincts — a contribué à son adoption rapide.
Comme nous l’avons dit, ce langage a été fortement influencé par d’autres initiatives antérieures qui utilisent certains de ces signes — # est emprunté à atx et > à un usage plus informel dans les courriels, par exemple —, ce qui explique l’adhésion de personnes déjà habituées à écrire au format texte.
Cette adhésion s’est traduite d’une part par une intégration dans différents outils d’écriture — CMS, plateformes d’échange ou de forums, etc. —, et d’autre part par la création d’extensions de ce langage.
Textile avait déjà démontré l’intérêt d’un langage de balisage léger intégré à des systèmes de publication existants, Markdown a confirmé cette tendance d’utiliser des alternatives au mode WYSIWYG.
Les éditeurs de texte enrichis intégrés à des logiciels comme DreamWeaver ou à des CMS comme WordPress ont longtemps été critiqués pour leur manque de respect du standard HTML ou pour leur balisage excessif, Markdown s’est imposé comme une forme de standard de fait.
L’objet de Markdown est le texte numérique, ce qui induit quelques lacunes pour qui voudrait structurer des notes de bas de page, des tableaux, voir des citations bibliographiques. C’est ce qui explique la création de saveurs alternatives à celle originelle de John Gruber, elles s’inscrivent dans des pratiques bien particulières, ou répondent à des contraintes techniques tierces que nous analysons par la suite.
#4.3.3. Les saveurs de Markdown
L’essor du langage de balisage léger Markdown est accompagné par différentes initiatives qui visent à l’étendre ou à l’adapter à des usages particuliers. Ce phénomène peut s’expliquer pour deux raisons principales : augmenter le champ des possibles sémantiques, permettre une intégration dans des outils d’écriture déjà existants. John Gruber spécifie immédiatement que l’objectif de Markdown, tel que prévu initialement, n’est pas de donner une équivalence à la majorité des éléments (balises) HTML. Pourtant, certaines opérations sémantiques, volontairement écartées par le créateur de Markdown, deviennent des prérogatives pour d’autres personnes ou d’autres démarches. Trois exemples d’éléments sémantiques permettent de comprendre les enjeux autour des velléités d’extension de Markdown : la note de bas de page, le tableau et les métadonnées.
La note de bas de page peut être transposée dans le langage HTML par un système simple de liens internes : l’appel de note est un lien hypertexte qui renvoie vers une autre partie du document grâce à une ancre placée dans la note, et un second lien permet de retrouver l’appel associé à la note. Cette transposition est verbeuse et peu agréable à écrire avec des balises HTML, c’est pourquoi les saveurs MultiMarkdown ou Markdown ExtraNous ne faisons pas la liste de toutes les saveurs existantes de Markdown. prévoient un balisage spécifique — toujours basé sur des caractères de ponctuation. Markdown peut ainsi être utilisé pour rédiger des textes avec une richesse sémantique plus importante, et ouvre la perspective d’usages dans le domaine des lettres où la note est une nécessité.
Le deuxième exemple est le tableau, particulièrement verbeux en HTML en raison de la complexité de cet objet, et dont une transposition plus simple — au détriment de toutes les options existantes en HTML — est faite avec Markdown Extra ou GitHub Flavored Markdown. Cet usage des tableaux, fondateur des premières initiatives de mise en forme avancée du début du Web, est principalement présentationnel. Du point de vue du sens il s’agit de faire correspondre mais aussi de croiser toute une série d’informations.
Enfin les métadonnées représentent un pan important des recherches liées à la mise en sémantique des textes avec l’informatique.
Décrire des métadonnées avec Markdown prend deux orientations, la première étant d’intégrer ces métadonnées au document initial, et la seconde consistant à laisser le choix entre une intégration ou une séparation.
La saveur MultiMarkdown fait le premier choix, en établissant un format de sérialisation de données à l’intérieur de Markdown via l’usage d’un entête sous la forme de balises déterminées.
La deuxième option est implémentée via divers formats de balisage, et notamment YAML — pour YAML Ain’t Markup Language — un langage de sérialisation de données qui, couplé à certains convertisseurs comme Pandoc, permet de renseigner des métadonnées qui peuvent ensuite être transcrites en HTML dans les éléments metadata placés dans l’entête.
Il s’agit d’une volonté d’enrichissement des documents au-delà de leur structuration de contenu, ainsi que d’une tentative de tout faire dans un même format.
Qu’est-ce qui explique ces saveurs multiples ? Un premier élément de réponse est de considérer chacune d’elles comme répondant à des usages particuliers dans des contextes différents, soulignant ainsi que tout format ne peut se réduire à une seule implémentation d’une série de principes théoriques. Une réponse moins consensuelle consiste à accepter que la spécification originale engendre de nombreuses ambiguïtés, listées en détail via le projet Babelmarkhttps://babelmark.github.io/faq/ — initialement lancé par John MacFarlane —, et que certaines saveurs entendent résoudre. Notons que ces pratiques foisonnantes autour de Markdown reflètent également des intégrations dans des environnements de programmation différents, comme Markdown Extra dont le convertisseur est écrit en PHP comparé à Pandoc qui est écrit en Haskell. Le langage se développe en même temps que des chaînes d’édition sont constituées autour ou avec lui — ces chaînes étant elles-mêmes en lien avec des projets éditoriaux variés. Cette situation illustre en partie la difficulté d’atteindre un standard, c’est-à-dire l’établissement d’une suite de règles univoques sous la forme de spécifications précises, censées permettre le développement d’applications autour de Markdown. Cette absence de standardisation fait elle-même l’objet d’une tentative de standardisation, ou tout du moins d’une publication à titre d’information sous la forme d’une RFC qui recense et documente certaines des saveurs de Markdown (Leonard, 2016) Leonard, S. (2016). Guidance on Markdown: Design Philosophies, Stability Strategies, and Select Registrations. Internet Engineering Task Force. https://doi.org/10.17487/RFC7764 . Une initiative communautaire émerge toutefois, tentant de résoudre les principaux problèmes de Markdown tout en étendant cette syntaxe : CommonMark.
#4.3.4. L’impossibilité d’une standardisation
Si le format Markdown s’impose comme une norme de fait
(Fauchié,
2018)
Fauchié,
A.
(2018).
Markdown comme condition d’une norme de l’écriture numérique.
Réél - Virtuel(6). Consulté à l’adresse
http://www.reel-virtuel.com/numeros/numero6/sentinelles/markdown-condition-ecriture-numerique
, tant les usages sont nombreux, nous devons comprendre les raisons d’une absence de standardisation.
Aucune spécification commune n’existe, sur laquelle une communauté suffisamment large peut s’accorder, et ce qui permettrait de disposer d’une saveur de référence de Markdown.
Le succès de Markdown — en termes d’adoption dans les pratiques d’écriture numérique et d’intégration dans diverses applications — est lié à ses spécifications ouvertes, qui engendrent toutefois des obstacles pour son interprétation.
L’enjeu ici concerne la conversion du format, principalement vers HTML, opération rendue complexe si des ambiguïtés persistent dans le balisage.
Par exemple le texte suivant ***bold** in ital* peut être traduit en HTML de diverses manières, c’est ce que démontre l’initiative Babelmark déjà évoquée.
Le fait qu’un même texte balisé avec Markdown puisse être interprété de différentes manières selon les outils ou les environnements est un problème, une lacune en termes d’interopérabilité.
Un standard permet diverses implémentations, à la fois respectueuses du format et interopérables.
Établir un standard est une tâche longue et complexe, l’objectif est de donner toutes les informations utiles à sa compréhension pour des humains qui l’écrivent et pour les machines qui le traitent. SGML ou HTML ont par exemple nécessité plusieurs années d’un travail collectif pour déterminer tous les éléments syntaxiques, que ce soient leur définition, leur signification, le rendu escompté ou leur imbrication. Dans le cas de HTML, c’est d’ailleurs un exercice continu dont le W3C a la charge. Une initiative collective de standardisation pour un autre langage de balisage léger, AsciiDoc, est en cours depuis 2020https://groups.google.com/g/asciidoc/c/EKx-Hfx-nMM, et démontre une volonté de disposer d’une base commune pour construire des outils de sémantisation. Plus qu’un simple travail de définition, un certain nombre de choix et de compromis sont réalisés, nécessitant un arbitrage par rapport au dessein initial comme les exemples ci-dessus le démontrent. Précisons enfin que ces efforts de standardisation sont toujours accompagnés du développement de programmes ou d’outils qui sont capables d’analyser, de convertir ou d’écrire ces formats. C’est le cas de HTML qui est interprété puis transformé en un rendu graphique via des navigateurs web. Markdown, en tant que langage de balisage, a été conçu avec un parser écrit en Perl, c’est également le cas avec AsciiDoc et le développement d’Asciidoctorhttps://asciidoctor.org.
Une tentative majeure de standardisation de Markdown a commencé en 2012 — soit 8 ans après la création originelle de John Gruber — sous le nom de CommonMarkhttps://commonmark.org. Ce projet rassemble plusieurs acteurs industriels ou académiques, et vise à établir le fonctionnement précis de cette syntaxe, et ainsi lever toute ambiguïté. Il s’agit de définir de façon univoque le balisage sémantique, et donc le choix des caractères de ponctuation et leur comportement pour marquer le sens du texte. CommonMark a une histoire complexe, faite de nombreux échanges entre les instigateurs de ce projet — John MacFarlane, David Greenspan, Vicent Marti, Neil Williams, Benjamin Dumke-von der Ehe, et Jeff Atwood —, mais aussi avec le créateur de Markdown, John Gruber. Les frictions, probablement nécessaires pour parvenir à un consensus, ne peuvent être détaillées précisément ici, mais concernent justement le degré d’ouverture que peut conserver ou non ce langage de balisage léger.
Le langage créé par John Gruber change de fonction et de statut au fur et à mesure de son évolution : en tant que code, il est le lieu même du dialogue humain-machine, passant d’idiolecte à standard, perdant en souplesse ce qu’il gagne en interopérabilité, en individuation ce qu’il gagne en cohérence.
Il est ainsi compréhensible que John Gruber n’ait pas souhaité participer à ce travail de fixation de son beau mais néanmoins utopique projet. Markdown s’est à ce point répandu dans les usages qu’il est même devenu une action plus qu’un format, tant il est synonyme d’une écriture qui se veut simple, compréhensible et sémantique.
Entre 2014 et 2021 ce sont trente versions des spécifications de CommonMark qui sont publiées successivement, proposant de nombreuses solutions pour une implémentation complète de ce langage, clarifications après clarifications. La longue liste des changements entre ces différentes versions (MacFarlane, 2021) MacFarlane, J. (2021). CommonMark changelog. Consulté à l’adresse https://spec.commonmark.org/changelog.txt révèle un travail titanesqueToutefois incomparable par rapport aux standard TEI ou HTML. pour un langage pourtant qualifié de léger. Tous ces efforts convergent pour permettre aux différents convertisseurs, logiciels ou applications en ligne d’interpréter convenablement Markdown. Depuis 2021 ces spécifications se sont pourtant arrêtées. Il paraît en effet impossible de résoudre les ambiguïtés liées aux choix de balises de départ, c’est ce que relève John MacFarlane dans un essai où il liste les six fonctionnalités de Markdown qui présentent le plus de difficultés (MacFarlane, 2018) MacFarlane, J. (2018). Beyond Markdown. Consulté à l’adresse https://johnmacfarlane.net/beyond-markdown.html .
À la suite de ce texte important pour le format Markdown et la communauté investie dans cette recherche de standardisation, John MacFarlane crée un nouveau format, Djothttps://djot.net. Largement inspiré de la saveur CommonMark, Djot résout les ambiguïtés inhérentes à Markdown en repensant un certain nombre d’éléments de balisage, et intègre également plusieurs nouvelles fonctionnalités en plus des tableaux ou des notes de bas de page. Au-delà de la conception remarquable et de la consistance du format lui-même, il faut observer à quel point il bénéficie du travail conjoint de développement du convertisseur Pandoc.
Nous pouvons observer qu’il y a une tension entre un format ouvert aux spécifications imprécises et un besoin de disposer d’un standard commun et partagé. Le format Djot créé par John MacFarlane ne suscite pas une adhésion large, malgré un succès d’estime. Le format Markdown trouve son intérêt dans ce que nous considérons un interstice sémantique, il s’agit d’un flou qui peut être exploité dans des actes éditoriaux. Il est par exemple possible d’inventer une balise, et d’ajouter un morceau de programme à un convertisseur pour prendre en compte ce nouvel élément syntaxique. Avec des formats standardisés comme XML-TEI, cela est possible mais au prix d’un effort beaucoup plus important. Markdown permet de construire des fabriques d’édition, où l’expérimentation a une grande place.
Avant de détailler le fonctionnement de Pandoc, notons que ce désir de disposer de langages de balisage léger ne s’arrête pas à Markdown. Nous pouvons citer la création de Gemini en 2019 (Bortzmeyer, 2020) Bortzmeyer, S. (2020). Le protocole Gemini, revenir à du simple et sûr pour distribuer l’information en ligne ? Consulté à l’adresse https://www.bortzmeyer.org/gemini.html , il s’agit à la fois d’un protocole de communication et d’un langage de balisage. En tant que format sémantique, Gemini est une adaptation minimale de Markdown, qui délègue totalement la représentation ou la conversion de sa syntaxe — constituée de sept éléments sémantiques. La création de ce format est donc liée à des outils qui permettent de le manipuler et de le visualiser — le caractère minimal des spécifications du format étant ici censé faciliter son implémentation dans différents environnements. Un format, quelles que soient ses spécifications, est toujours développé avec une modélisation qui permet de le représenter.
#4.3.5. Un format à convertir
Comme tout langage de balisage léger, Markdown est fait pour être converti. C’est pourquoi John Gruber a publié conjointement les spécifications du format et le programme qui transforme chaque élément sémantique en balise HTML correspondante — programme écrit en Perl. Un langage de balisage ne se suffit pas à lui-même, ses spécifications dépendent donc du fonctionnement d’un ensemble d’éléments : un analyseur (parser en anglais), une modélisation abstraite, un convertisseur et un module d’écriture. Dit autrement par Sean Leonard ci-dessous, c’est cet ensemble qui détermine précisément le fonctionnement de la syntaxe :
Second, the primary arbiter of the syntax’s success is running code. The tool that converts the Markdown to a presentable format, and not a series of formal pronouncements by a standards body, is the basis for whether syntactic elements matter.
Un analyseur syntaxique, ou parser, est un programme qui est capable de construire, à partir de données, une structure syntaxique qui se traduit par une modélisation abstraite, permettant ensuite des manipulations de ces données — dont des conversions. L’objectif, dans le cas de Markdown, est donc de reconnaître chaque balise pour représenter le texte selon un arbre syntaxique abstrait. Le DOM — pour Document Object Model — est un moyen programmatique, syntaxique et sémantique de représenter cet arbre syntaxique abstrait. Prenons un exemple : un document qui contient un titre, un paragraphe et une citation longue peut être représenté ainsi : un document qui est composé de deux éléments que sont un entête et un corps, le corps étant lui-même composé de deux sous-ensembles que sont un paragraphe et une citation longue, etc. La modélisation abstraite permet de définir les besoins sémantiques, et le DOM permet de le représenter pour manipuler les données et les convertir dans d’autres formats. La conversion d’un fichier au format Markdown vers HTML passe donc d’abord par ces étapes d’identification syntaxique, de représentation abstraite et de manipulation de données.
Les variantes de Markdown sont accompagnées de (presque) autant de façons de le convertir vers d’autres formatsLe projet Babelmark répertorie une trentaine de parsers différents : https://github.com/babelmark/babelmark-registry/blob/master/registry.json, et en premier lieu HTML. Parmi ces convertisseurs, Pandoc fait figure d’exception en raison des multiples formats d’export disponibles — comme c’est indiqué sur la page d’accueil du site web dédiéhttps://pandoc.org, « pandoc is your swiss-army knife » —, et de la volonté d’en faire un outil orienté vers les standards. C’est ce qui explique que son créateur et principal mainteneur, John MacFarlane, professeur de philosophie à l’Université de Californie, s’est fortement impliqué dans la tentative de standardisation de Markdown avec CommonMark.
Un aparté est ici nécessaire à propos de cette séparation entre format source et rendu final, qui est aussi une distinction entre le format d’écriture — celui qui est utilisé au moment où le texte est tapé —, et le format qui circule — a priori le format converti. Les langages de balisage, qu’ils soient légers ou non, ont cette particularité d’être à la fois des « formats d’échange » et des « formats de travail » pour reprendre les expressions utilisées par Bruno Bachimont :
Les formats de travail sont internes à l’application et ne prétendent à aucune universalité. C’est une solution locale formulée à travers un format déclaratif. Le format d’échange prétend à une certaine universalité, dans la mesure où l’on doit pouvoir tout dire et se faire lire par tout le monde. Comme ces deux objectifs sont contradictoires, il faut bien transiger, et chaque format se définit par le type de compromis qu’il a adopté. Par conséquent, vouloir choisir le format d’échange pour mener les traitements internes de l’application est souvent un choix maladroit et introduit des contraintes et difficultés inutiles à l’élaboration du projet, alors qu’il suffit d’avoir un moyen de traduire les structures du format interne dans le format d’échange pour exploiter de manière large les informations manipulées et produites par l’application.
Avec Markdown l’universalité (pour reprendre le terme de Bruno Bachimont) est aussi du côté de l’outil. C’est d’ailleurs le mot qu’utilise Pandoc pour se définirL’expression exacte est « convertisseur de documents universel » (universal document converter)., « universel ».
Mis en place dès 2006 — soit deux ans après la création de Markdown — Pandoc réalise une série d’opérations pour passer d’un format de balisage à un autre, et plus spécifiquement d’un langage de balisage à plusieurs formats de sortie.
Pandoc shows its real utility, in my opinion, when what is needed is to obtain several output formats from a single source, as in the case of a document distributed online (HTML), in print form (PDF via LATEX) and for viewing on tablets or ebook readers (EPUB). In such cases one may find that writing the document in a rich format (e.g. LATEX) and converting later to other markup languages often poses significant problems because of the different ‘philosophies’ that underlie each language.
Ce qui semble simple, typiquement remplacer **ce texte** par <strong>ce texte</strong>, peut se révéler bien plus complexe dans certains cas, et plus encore lorsqu’il s’agit de conjuguer des résultats comme un format sémantique (comme HTML) et un format de composition (comme LaTeX).
Pandoc consiste en une suite d’opérations pour permettre une forme de correspondance entre deux formats de balisage.
Il s’agit donc de réaliser une analyse syntaxique du format d’entrée pour disposer d’une représentation du document, le DOM, qui est ensuite manipulé pour créer un nouveau fichier dans un autre langage de balisage.
Pandoc adopte une organisation modulaire et transforme ainsi tout texte en un arbre de données manipulables.
Le format JSON est une manifestation du DOM, parmi d’autres, qui permet de prendre la mesure de la richesse de cette modélisation abstraite, sans pour autant en être une représentation complète.
La simple phrase au format Markdown Des *fabriques d'édition*. peut avoir comme manifestation le document suivant au format JSON :
{"pandoc-api-version":[1,22,2],"meta":{},"blocks":[{"t":"Para","c":[{"t":"Str","c":"Des"},{"t":"Space"},{"t":"Emph","c":[{"t":"Str","c":"fabriques"},{"t":"Space"},{"t":"Str","c":"d’édition"}]},{"t":"Str","c":"."}]}]}
À partir de ces opérations — analyse syntaxique, représentation abstraite, manipulation des données —, Pandoc est capable de produire plus de cinquante formats. Il peut s’agir de formats de balisage léger (Markdown, Textile), des formats HTML ou XML (selon plusieurs schémas), de formats utilisés dans des systèmes de wiki, ou encore des formats de données comme CSV. Il est même possible de créer son propre outil d’analyse et de manipulation de données, via le langage de programmation Lua. Le rôle éminemment épistémologique de Pandoc est de considérer chaque format comme une expression syntaxique et sémantique qui peut être représentée de diverses manières, avec ou sans perte d’informations. Le point de départ privilégié est Markdown, probablement pour ses caractéristiques légères et extensibles par rapport à d’autres formats (Dominici, 2014, p. 50) Dominici, M. (2014). An overview of Pandoc. TUGboat, 35(1). 44–50. .
Une des particularités de Pandoc est son utilisation via un terminal, il ne s’agit pas d’un logiciel avec une interface graphique. Cela a probablement été une des raisons de son adoption d’abord par une communauté de techniciens et de techniciennes, notamment dans les domaines du développement informatique ou de certains champs académiques (mathématiques et physique par exemple). Comme tout programme en ligne de commande, Pandoc prend plusieurs paramètres en compte, voici deux exemples de commande commentées :
pandoc fichier-source.md # cette commande transforme le fichier source en donnant le résultat directement dans le terminal pandoc -f markdown -t html fichier-source.md -o fichier-exporte.html # cette commande spécifie le format en entrée et le format en sortie, ainsi que le nom du fichier exporté pandoc -f markdown -t html fichier-source.md -o fichier-exporte.html --citeproc --standalone --wraps=none --template=modele.html # cette commande ajoute la fonction de gestion bibliographique, la précision que le fichier HTML produit doit comporter aussi un entête, l'option que les lignes ne doivent pas être sautées tous les 80 caractères, et le modèle ou template qui doit être appliqué
Dans la dernière commande de l’exemple ci-dessus, Pandoc applique un modèle (template en anglais) vers une disposition de données exprimée via un langage particulier — et basée sur des conditions et des boucles. Cela en fait un puissant outil de conversion où la structure d’un document peut être rédigée distinctement du contenu et de sa mise en forme.
Un programme, des options et des arguments, le fonctionnement de Pandoc est au premier abord assez classique, en informatique il s’agit d’un tube (pipe en anglais) qui traite une information en entrée et donne un résultat en sortie. Mais une autre de ses particularités est de pouvoir être étendu, via le recours à des filtres, qui sont des scripts qui appliquent des transformations contextuelles. Ces filtres sont une condition de l’appropriabilité de Pandoc, puisqu’il est relativement simple de créer de nouvelles règles de conversion, sans pour autant devoir modifier le code de Pandoc. Un exemple parmi d’autres est un filtre chargé de gérer les spécificités typographiques du français, comme les espaces insécables avant certains signes de ponctuation. Le filtre pandoc-filter-fr-nbsphttps://inseefrlab.github.io/pandoc-filter-fr-nbsp/ prend par exemple en charge la gestion microtypographique pour les spécificités de la langue française (espaces insécables avant certains signes de ponctuation notamment).
Le point de départ de Pandoc est la transformation du langage de balisage léger Markdown vers des formats de sortie comme HTML ou LaTeX (pour ensuite viser le format PDF), mais par son mode de fonctionnement ce convertisseur est un double apport : la multimodalité et l’acte éditorial sémantique. Pandoc est capable d’exporter un même format dans plusieurs formats de sortie, autrement dit il peut convertir une même source en différentes formes éditoriales. Il permet d’appliquer les principes du single source publishing, ou publication multimodale à partir d’une source unique, explicitée dans la section qui suit. Plus qu’une simple prouesse technique, il s’agit d’une nouvelle dimension qui complète le concept de format tel que définit dans le contexte de l’édition. L’acte éditorial sémantique est l’introduction de pratiques de sémantisation dans le processus même d’édition, et plus uniquement dans la structuration d’un texte et d’un fichier.
#4.4. Le single source publishing comme acte éditorial sémantique</>
Commit : 1ac73c3
Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-04.md
</>
Commit : 1ac73c3Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-04.md
La question des formats dans l’édition permet de prendre la mesure des enjeux techniques inhérents à toute activité éditoriale, et s’inscrit plus largement dans l’étude de processus de transformations de sources sémantiques pour aboutir à un artefact ; ces mêmes processus de transformations que nous présentons et analysons désormais comme pratiques d’édition. Il s’agit en effet de considérer l’édition comme une pratique sémantique, reposant ainsi sur la structuration des contenus permise par des formats, mais aussi sur un principe de fabrication des artefacts éditoriaux. Ce que nous qualifions d’« acte éditorial sémantique » correspond à l’application des principes de séparation des contenus et de leur représentation afin de produire de multiples artefacts, ces principes reposant sur un balisage sémantique auquel des procédés de conversion sont appliqués. Cet ensemble de pratiques est qualifié de single source publishing en anglaisPar la suite nous utilisons indistinctement les expressions single source publishing, et édition multi-formats ou multimodale à partir d’une source unique, préférant la première expression pour des raisons de clarté et de concision.. Nous répondons à la question suivante : que signifie intégrer les principes du format texte et des langages de balisage léger aux pratiques d’édition ?
Nous explorons tout d’abord l’édition multimodale, et ce que nous qualifions de processus interopérables, ce qui nous mène aux principes du single source publishing. Nous définissons ensuite ces principes en les déclinant en plusieurs éléments distincts autour de la question de la modélisation. Nous décomposons ainsi le processus permettant d’obtenir plusieurs versions d’artefacts en utilisant des langages de balisage. Nous établissons une critique sur plusieurs plans — légitimation de contenus, pratiques d’édition et fabrication d’outils adéquats —, avant d’aborder les implications théoriques sous-jacentes autour des concepts d’hybridité, d’hybridation et d’éditorialisation.
Dans cette perspective d’une sémantisation de l’édition elle-même, les implications sont nombreuses et les références à nos travaux précédents s’avèrent précieux. La majorité des études sur ce sujet concerne les domaines de l’édition scientifique ou de la documentation technique — comme le prouve par exemple notre article publié à l’automne 2023 et intitulé « The Importance of Single Source Publishing in Scientific Publishing » (Fauchié & Audin, 2023) Fauchié, A. & Audin, Y. (2023). The Importance of Single Source Publishing in Scientific Publishing. Digital Studies / Le champ numérique. https://doi.org/10.16995/dscn.9655 — nous élargissons toutefois le spectre aux lettres. Précisons que nous n’abordons pas le sujet de l’« édition sémantique », il s’agit là de questions de représentation des textes et des données dans des espaces communicationnelles — de la « circulation médiatique des productions scientifiques » (Kembellec, 2020) Kembellec, G. (2020). Semantic publishing, la sémantique dans la sémiotique des codes sources d’écrits d’écran scientifiques. Les Enjeux de l'information et de la communication(20/2). 55–74. Consulté à l’adresse https://lesenjeux.univ-grenoble-alpes.fr/2019/dossier/04-semantic-publishing-la-semantique-dans-la-semiotique-des-codes-sources-decrits-decran-scientifiques/ — néanmoins liées à nos préoccupations. Des formats sémantiques à un acte éditorial sémantique, nous prolongeons notre plongée dans les replis des processus.
#4.4.1. Édition multimodale et processus interopérable
Nous l’avons vu précédemmentVoir 2.1. Évolution de l’édition, l’évolution de l’édition imprimée puis numérique a engendré de nouvelles formes de publication et a modifié les processus d’édition, introduisant le besoin de générer plusieurs formes pour un même contenu. C’est que nous appelons l’édition multi-formats ou multimodale, ou le fait de produire plusieurs formes ou versions dans une même démarche d’édition. Nous relevons trois niveaux dans ce type de démarche. Si le terme multi-formats définit plusieurs formes pour un même contenu, le terme multimodal est plus ambigu : il correspond à plusieurs modalités de diffusion d’un même contenu par la fabrication de plusieurs artefacts distincts. C’est donc d’abord en fonction de la réception — et donc plus spécifiquement des contextes de lecture — que plusieurs objets éditoriaux sont conçus puis générés. Nous n’utilisons pas ici l’expression édition multi-support, qui se situe à un niveau précédent de la multimodalité, comme l’explique Pierre-Yves Buard :
Il s’agit en effet le plus souvent d’une édition multisupport enrichie de modalités d’accès aux textes variées et qui ne se contente donc pas de proposer des solutions de lecture immersive. Dans cette optique le support peut être considéré comme une simple modalité : le texte se lit soit sur le papier, soit en ligne, soit sur un livre numérique par exemple.
Le cas du livre numérique au format EPUB illustre parfaitement l’objectif de diffusion de plusieurs livres d’un même texte. C’est l’objet de l’édition numérique homothétique sur laquelle portait l’une de nos précédentes critiquesVoir 3.2. Le livre numérique ou la pensée homothétique — ne pas questionner les façons de faire mais utiliser le numérique pour diffuser un même contenu sur plusieurs supports, souvent avec une forme très similaire. Dupliquer. Reproduire. La co-existence de plusieurs formats pose des questions de diffusion, de réception et de modes de lecture que nous n’analysons pas ici. Quoi qu’il en soit, la notion de multi-formats consiste donc d’abord en l’édition d’un même contenu en plusieurs formats, leur forme étant identique ou très similaire, les processus permettant leur production respective sont par ailleurs souvent distincts.
L’édition multimodale consiste à générer, toujours dans une même démarche éditoriale, plusieurs versions d’un même contenu. Il ne s’agit plus uniquement de générer des formats divers mais de considérer des formes qui engendrent une autre perception des contenus, des modélisations. Par forme nous entendons ici le rendu graphique, soit la présentation des contenus, mais aussi les caractéristiques de l’objet imprimé ou numérique. Par modélisation nous entendons la disposition des éléments qui constituent un texte ou un livre. Il s’agit du design :
Transduction entre le fond et la forme, au sens où il y a coavènement ou coconstitution entre la forme comme idée perçue et fond matériel sous-jacent, ou encore entre la forme manifestée et l’arrière-plan conceptuel sous-jacent, le design est toujours l’émergence d’une singularité nouvelle mais évidente […].
Des versions se distinguent donc par leur singularité. Pour donner un premier exemple de ce type d’édition multimodale, nous pouvons rappeler la première étude de cas de notre rechercheVoir 1.3. Éditer autrement : le cas de Busy Doing Nothing, le livre Busy Doing Nothing du collectif Hundred Rabbits. Une première version consiste en un journal de bord sous la forme d’une (longue) page web disponible librement en ligne, une autre version paginée est commercialisée au format imprimé ou numérique (format PDF). Les versions existent simultanément. Il faut préciser ici que la démarche éditoriale est la même, en revanche les sources — permettant la production de ces deux artefacts — sont bien distinctes. Cette distinction s’explique par deux manières différentes d’éditer les contenus : le langage HTML convertit en page/site web par un programme écrit en C dans le premier cas ; un fichier au format Markdown transformé en PDF via Pandoc et LaTeX dans le second cas. La décorrélation entre ces deux sources s’explique notamment par une modélisation hétérogène (un tableau dans le premier cas et une structuration textuelle linéaire dans le second), même si un moyen pourrait être trouvé pour les rassembler et appliquer des scénarios contextuels — sur lesquels nous revenons dans le prochain chapitreVoir 5.4. La fabrique : éditer des fabriques et fabriquer des éditions.
Pour prendre un second exemple d’édition multimodale, nous pouvons évoquer le travail de recherche et d’édition de Tara McPherson avec la revue Vectors, revue dont la multimodalité est une nécessité, les formats numériques existants ne permettant pas d’accueillir des formes d’écriture originales. Robin de Mourat explique longuement le fonctionnement et l’intérêt de la dimension multimodale de ce projet éditorial (Mourat, 2020, p. 259-276) Mourat, R. (2020). Le vacillement des formats : matérialité, écriture et enquête : le design des publications en Sciences Humaines et Sociales. Thèse de doctorat, Université Rennes 2. Consulté à l’adresse https://theses.hal.science/tel-03052597 , en axant sa recherche sur l’écriture multimodale.
L’usage de langages de balisage — léger ou non — ouvre la possibilité d’une interopérabilité dans le processus d’édition. Les formats peuvent cohabiter ensemble, et se répondre et se compléter par des jeux de conversion ou de transformation. Cela nous permet d’envisager un troisième niveau d’édition, la génération de plusieurs versions d’artefacts éditoriaux dans une même démarche et à partir d’une unique source. Il s’agit des principes du single source publishing que nous détaillons désormais.
#4.4.2. Pour une définition des principes de single source publishing
Le single source publishing, ou l’édition multi-formats ou multimodale à partir d’une source unique, consiste principalement à produire plusieurs formats de sortie à partir d’une source unique. Cette source peut regrouper plusieurs fichiers, l’idée étant qu’une modification sur un seul fichier (par exemple une correction orthographique ou l’ajout d’une image) se répercute sur plusieurs formats de sortie. Nous pratiquons tous et toutes une forme de single source publishing en éditant un document avec un traitement de texte, et en le transmettant dans son format original et au format PDF — deux artefacts éditoriaux sont générés depuis une seule source. L’objectif initial de la publication multisupport, multi-formats ou multimodale depuis une source unique est de réduire le temps d’intervention sur de multiples sources identiques — en termes de contenu —, et de limiter les erreurs induites par le maintien de plusieurs fichiers qui sont amenées à diverger. Une seule source unique signifie un seul point d’attention, en revanche cela complexifie le processus nécessaire pour produire des artefacts. C’est là qu’intervient la modélisation dans une chaîne d’édition : la définition de la structure finale est en partie ou totalement séparée de celle des contenus, cette modélisation faisant toutefois partie intégrante de l’acte d’édition.
Les provenances historiques du single source publishing sont diverses, nous en retenons deux principales : la séparation de la forme et du contenu, comme nous l’avons déjà vuVoir 4.2. Les conditions de la sémantique : format texte et balisage, afin de produire plusieurs formes d’un même contenu ; des principes issus de la programmation également utilisés dans la définition de schémas en XML. Ainsi une première mention de cette double action de séparation d’un contenu et de sa présentation, et de production de plusieurs formats à partir d’une source unique, est faite dans la formalisation du langage de balisage GML comme le signalent Mary Kalantzi et Bill Cope :
Using GML, tags would be inserted into the digital text specifying paragraphs, sections, headings, tables, lists, and the like. These tags did not indicate how these meaning functions were to look, or the form they were to take when rendered. Instead, there were to be separate “stylesheets” which rendered text in different ways depending on the end device, whether, for instance, that was a paper printer or a screen. So, re-manufacture was not reproduction. The redesign was not a replicant of the design. Or, to use terminology of this grammar, the tags indicate meaning functions; the stylesheets determine the particularities of meaning form as realized in variable media.
Il s’agit donc de décomposer l’édition d’un document en un contenu, sa structure et sa mise en forme. Rappelons que GML est développé à partir de 1969, bien avant l’apparition des premiers traitements de texte ou des logiciels de composition.
Une autre influence peut être trouvée du côté de la programmation informatique avec le concept de programmation lettrée (literate programming en anglais) développé par Donald Knuth dans les années 1980 (Knuth, 1984) Knuth, D. (1984). Literate Programming. The Computer Journal, 27(2). 97–111. https://doi.org/10.1093/comjnl/27.2.97 . Le concept consiste en l’insertion d’éléments de programmation au sein d’un document faisant office de documentation, et non l’inverse. Le principe de One Document Does it all (ou ODD) en TEI est lui-même un langage de programmation lettrée, il est utilisé pour la description de schémas XML : l’objet de ce format est d’abord de documenter un schéma et ensuite d’intégrer au fil du texte lettré des éléments de programmation à la fois pour les humains et pour les machines. Cette double dimension permet de produire autant une documentation textuelle qu’une suite d’instructions pour vérifier que des fichiers XML respectent bien le schéma défini dans ce document. Deux en un, si nous nous permettons ce constat trivial. Si ces modélisations éditoriales semblent éloignées du single source publishing, elles méritent néanmoins d’être citées en raison de leur point commun avec l’édition : lever toute ambiguïté dans une activité d’édition (de code) et de publication (d’une documentation).
À partir de ces différents éléments, nous établissons une définition des principes du single source publishing :
Définition Single source publishing ou édition multi-formats depuis une source unique
Liste des conceptsL’édition multi-formats ou multimodale à partir d’une source unique est une méthode et un processus visant à produire plusieurs formats ou versions depuis une seule et unique source, en appliquant des conversions ou des transformations. Il s’agit de générer des formes variées, en répétant plusieurs opérations distinctes et néanmoins liées par une modélisation éditoriale commune, tout en restreignant les données en entrée à une seule origine. Le single source publishing est un ensemble de principes nécessitant une dimension interopérable. La source, et les éléments qui la composent, doit répondre à des standards pour que les programmes invoqués dans le processus soient capables d’appréhender la structure, afin de transposer une expression sémantique dans plusieurs formats de sortie — des manifestations. Les principes de l’édition multi-formats ou multimodale à partir d’une source unique sont d’ordre technique, mais, comme tout principe technique, ils sous-tendent des enjeux théoriques et épistémologiques, principalement autour de la modélisation éditoriale et donc de la construction du sens à partir de modèles de données.
Le principe d’édition multi-formats ou multimodale à partir d’une source unique est largement adopté dans des environnements qui font appel à XML, l’application de feuilles de transformationsL’appellation répandue pour qualifier XSLT est « feuille de styles », nous préférons toutefois « feuille de transformations » qui lève l’ambiguïté avec les feuilles de styles en cascade (CSS) utilisées pour le Web. XSLT permettant de produire différents formats ou versions de documents dans divers domaines (édition scientifique, documentation, système de gestion et de publication de documents administratifs, base de connaissance, etc.). Il s’agit d’appliquer des règles de transformation sur un balisage sémantique en XML pour aboutir à des artefacts dans des formats divers comme des pages web (HTML), des fichiers imprimables (PDF), des documents éditables dans des traitements de texte (DOCX) ou encore des formats XML qui font appel à d’autres schémas XML. Les cas d’usage sont variés, comme l’illustre Dave Clark dans le contexte de l’édition d’un texte légal qui accompagne le manuel d’un grille-pain :
Using tools that can check the XML against rule sets and then use style sheets to output the XML in a variety of genres and formats, this legal content can be automatically presented whenever it is relevant to the particular materials being examined. The same content module could appear on every page of a website and in the small print of the manual. Should the legal department require a wording change, the content would only need to be changed once, in the content management system, to update all the documents that use it.
L’usage de la TEI répond également à ce type de besoin : en partant d’un ou plusieurs fichiers balisés, il est possible de générer de multiples formats, ainsi que plusieurs versions pour chacun d’eux, grâce à une modélisation préalablement établie. Cet enjeu de définir un modèle abstrait de document est particulièrement bien présenté dans une étude de Klaus Thoden dans le cas d’une démarche de publication numérique en libre accès (Thoden, 2019) Thoden, K. (2019). Modeling scholarly publications for sustainable workflows. ELectronic PUBlishing, Academic publishing and digital bibliodiversity. https://doi.org/10.4000/proceedings.elpub.2019.2 . Enfin nous pouvons signaler un usage massif de XML sous différents formats, dont JATS en Amérique du Nord et XML-TEI en Europe, permettant également de produire plusieurs formats (S.A., 2017, p. 60-63) (2017). The Chicago manual of style (Seventeenth edition). The University of Chicago Press. . Si les principes du single source publishing sont adoptés dans des usages et des domaines divers et présentent plusieurs avantages, il s’agit désormais d’y porter un regard critique.
#4.4.3. Pour un regard critique sur le principe de single source publishing
Les principes du single source publishing invoquent deux conceptualisations que nous distinguons, et qui sont liées aux opérations de conversion que nous avons déjà évoquées avec Pandoc : la transposition d’un format à un autre, et le développement d’un modèle abstrait — pivot — qui permet d’envisager de multiples manifestations. La première conceptualisation consiste en une traduction entre deux formats, via la correspondance d’expressions sémantiques. La seconde conceptualisation est une modélisation idéale, abstraite des représentations dans des formats, et qui, de fait, est plus riche que la première. Dans ce deuxième cas il s’agit, techniquement, d’une série de fonctions définies à travers des analyseurs syntaxiques, un arbre syntaxique abstrait ou des modules d’écriture pour manipuler les données. Pandoc a par exemple été d’abord un convertisseur qui transpose des règles syntaxiques d’un format à un autre avant d’intégrer cette dimension d’arbre syntaxique abstrait — ou AST pour Abstract Syntaxic Tree en anglais.
Si les principes de single source publishing représentent un intérêt certain dans des pratiques d’édition, leur origine est néanmoins plus bureaucratique que lettrée, répondant à des besoins de productivité plus que d’expérimentations éditoriales — voir littéraires. Ces principes ont, par ailleurs, un certain nombre de limites. Les enjeux que nous explorons sont ceux de la légitimation de contenu, de l’évolution des pratiques de publication, ou encore de la création et de l’adoption d’outils adaptés. Nous nous concentrons ici sur le domaine de l’édition scientifique sans pour autant que ces trois critiques ne puissent être portées sur d’autres champs. Nous abordons la question de l’implémentation technique en situation réelle dans l’étude de cas qui suitVoir 4.5. Stylo et son module d’export : fabriquer des livres.
Une chaîne d’édition multimodale à partir d’une source unique peut être considérée comme horizontale, puisqu’en théorie les différentes personnes impliquées dans l’acte d’édition peuvent modifier la source unique à tout moment — y compris à la toute fin du processus. En effet la légitimation ne consiste plus à savoir modifier la bonne source pour en engendrer les artefacts finaux. L’éditeur ou l’éditrice, initialement dépositaire de cette légitimation via l’intervention sur l’une des multiples sources, doit désormais considérer le travail de modélisation comme central dans leur activité — justifiant par là même leur rôle. Ce glissement peut être vu comme une opportunité de reconsidérer le flux d’édition dans son ensemble, et ainsi d’imaginer de nouveaux formats sans craindre des sources supplémentaires à gérer en parallèle. Cela nécessite néanmoins une évolution des pratiques d’édition et de publication.
Est-il possible de pratiquer le single source publishing avec des traitements de texte ? La question que nous posons ici n’est pas tant celle de l’outil que celle des pratiques, c’est-à-dire l’usage qui est fait du logiciel d’écriture et d’édition le plus utilisé. Si nous prenons le cas de l’édition scientifique, un logiciel comme Microsoft Word peut s’inscrire dans une démarche d’édition multi-formats ou multimodale à partir d’une source unique, à condition de l’utiliser convenablement (via l’utilisation de feuilles de styles) et de disposer d’outils complémentaires (permettant un export XML acceptable). L’initiative MétopesMétopes, pour Méthodes et outils pour l’édition structurée, est une chaîne d’édition multisupport, créée, maintenue et promue par le pôle Document numérique de la Maison de la Recherche en Sciences Humaines de Caen. répond a ce double enjeu en proposant un module complémentaire dans Word afin d’appliquer une sémantique, et via des scripts pour un export XML compatible avec les plateformes de diffusion scientifiques (Vincent, 2020) Vincent, E. (2020). Métopes, édition et diffusion multisupports : Un exemple de déploiement à l’EHESS. Consulté à l’adresse https://www.annales.org/enjeux-numeriques/2020/resumes/juin/09-en-resum-FR-AN-juin-2020.html — en l’occurrence en France, un projet étant lancé également au Québec et visant le Canada. Il est donc ici question d’adapter des pratiques et des outils existants sans pour autant remettre en cause les processus à l’œuvre. Cela est toutefois aussi une possibilité que de reconsidérer les processus dans leur ensemble.
Depuis les années 1980 la communauté des sciences humaines utilise un paradigme unique pour l’écriture et l’édition, le mode WYSIWYG — dont les traitements de texte sont l’expression même, qu’il s’agisse du plus répandu et néanmoins propriétaire (Microsoft Word), de sa version libre (LibreOffice Writer) ou en ligne (Google Docs). Ce mode d’écriture ou d’édition maintient une confusion entre la structure du contenu et son rendu graphique — comme nous l’avons déjà soulignéVoir 4.2. Les conditions de la sémantique : format texte et balisage —, alors que les formats numériques requièrent d’abord un encodage sémantique, ensuite transposé dans de multiples formes et formats. C’est ce que nous démontrons dans l’étude de cas qui suitVoir 4.5. Stylo et son module d’export : fabriquer des livres, où l’éditeur de texte sémantique Stylo et ses options d’export permettent d’implémenter un mode WYSIWYM — pour What You See Is What You Mean, déjà abordéVoir 4.2. Les conditions de la sémantique : format texte et balisage — soit la réalisation d’un acte éditorial sémantique. Plusieurs communautés scientifiques ou savantes ont adopté ce mode, conduisant à des outils ou plateformes comme Métopes, Manifoldhttps://manifoldapp.org, PubPubhttps://www.pubpub.org, Ketidahttps://ketida.community ou Quirehttps://quire.getty.edu — que nous ne détaillons pas ici. Cet investissement dans la mise en place de solutions techniques ou dans l’acquisition d’une littératie plus forte est loin d’être un détail, tant cela représente un temps et un coût importants.
L’exposition de ces trois limites — légitimation, pratiques et outils — doivent désormais être mise en regard de trois concepts qui permettent de donner une profondeur épistémologique au principe d’édition multi-formats ou multimodale à partir d’une source unique, afin de conceptualiser l’acte éditorial sémantique lui-même.
#4.4.4. Hybridité, hybridation et éditorialisation
Les principes du single source publishing ne se limitent pas qu’à des questions d’implémentation technique ou à des remises en cause des fonctionnements au sein des structures éditoriales. Plusieurs considérations épistémologiques émergent, et plus spécifiquement dans le champ des médias ou de l’écriture numérique. Les concepts d’hybridité, d’hybridation ou d’éditorialisation apportent une dimension théorique à la fois profonde et nouvelle dans l’étude de l’édition. Nous formulons un avertissement en préambule : tout hylémorphisme doit être évité à travers cette triple conceptualisation, et nous devons ainsi considérer sur un même plan les différents éléments textuels constitutifs d’une chaîne d’édition, pour permettre une séparation entre ce que nous pouvons considérer comme les contenus et leur représentation. Ainsi les fichiers sources qui accueillent les textes, mais aussi les fichiers de modélisation, ou encore les scripts nécessaires aux conversions et aux transformations, constituent ensemble l’acte d’édition. Il est ainsi difficile de séparer totalement un fichier balisé avec un langage de balisage ou son convertisseur. Cette précision étant faite, considérons justement l’effet de la prise en compte de multiples artefacts finaux sur la source elle-même.
L’hybridation ou la rencontre de deux média est un moment de vérité et de découverte qui engendre des formes nouvelles. Le parallèle entre deux média, en effet, nous retient à une frontière de formes et nous arrache à la narcose narcissique. L’instant de leur rencontre nous libère et nous délivre de la torpeur et de la transe dans lesquelles ils tiennent habituellement nos sens plongés.
Marshall McLuhan développe le concept d’hybridité ou d’hybridation comme la production d’un nouveau média lorsqu’il y a un croisement de plusieurs médias (McLuhan, 1968, p. 69-77) McLuhan, M. (1968). Pour comprendre les médias: les prolongements technologiques de l’homme. Points [2013]. . Pour lui, l’intérêt doit être porté sur l’effet des médias entre eux plutôt que sur nous, ainsi les initiatives artistiques qui mêlent plusieurs médias profitent de cette influence née de l’hybridité. En partant de cette conceptualisation, nous pouvons interroger l’influence que peuvent avoir les formes ou les formats des multiples artefacts sur les sources elles-mêmes, dans un contexte littéraire — au sens large — où ces artefacts sont produits par une chaîne d’édition qui adopte les principes du single source publishing. Dans le cas d’un acte éditorial sémantique, comment une syntaxe doit-elle être utilisée ou adaptée pour permettre la production simultanée de plusieurs objets éditoriaux, comme une version imprimée et une version numérique enrichie ? Si nous avons en partie répondu à cette question dans deux études de casVoir 2.5. Le Pressoir : une chaîne d’éditorialisation précédentesVoir 3.5. Le Novendécaméron ou éditer avec et en numérique, nous qualifions ce phénomène comme une hybridité des éléments, et plus spécifiquement comme une modélisation. Le rôle des modèles — ou templates en anglais — est de traduire une construction sémantique en un motif éditorial, en déterminant comment distribuer les différentes données par le biais d’instructions spécifiques et univoques. Ainsi, dans notre cas, l’hybridité est possible grâce au travail effectué sur les gabarits, il s’agit de façonner ou de fabriquer les artefacts via cette modélisation.
Ce concept d’hybridité que ne formule pas directement Marshall McLuhan — malgré le titre du cinquième chapitre de Pour comprendre les médias, « L’énergie hybride » dans la version française — est lié à celui d’hybridation, concept qui prend un sens particulier à l’ère de l’impression post-numérique comme le théorise Alessandro Ludovico.
En d’autres termes, ce livre [Written Images de Martin Fuchs et Peter Bichsel] offre un exemple très complet de ce que pourrait être l’impression postnumérique : l’imprimé considéré comme un objet en édition limitée ; le financement participatif en réseau ; le traitement de l’information par ordinateur ; l’hybridation de l’imprimé et du numérique — le tout réunit en seul médium, un livre traditionnel.
Dans Post-Digital Print Alessandro Ludovico analyse des initiatives de publication hybride, où plusieurs artefacts produits à partir d’une même source se complètent entre eux. Les versions électroniques de livres, de revues, de magazines ou d’articles viennent compléter des formes déjà existantes : les artefacts imprimés et numériques deviennent hybrides. Même si la source est unique, il est possible d’établir plusieurs scénarios en fonction du format de sortie. Par exemple un bloc de texte spécifique peut être affiché différemment en fonction de l’artefact final (choix typographiques, disposition), ou de même qu’un bloc de texte peut être étendu sur une version plutôt que sur une autre. Des structures d’édition expérimentent déjà différentes versions d’un livre imprimé avec le même contenu : du livre de poche bon marché à l’édition imprimée à tirage limité avec couverture rigide luxueuse et gaufrée. Certaines versions numériques au format EPUB sont dépourvues de contenus dont le rendu ne serait pas optimal sur un écran à encre électronique ; à l’inverse, des images en haute qualité avec option de zoom sont intégrées à des versions numériques au format web, une haute définition qui est plus coûteuse sur une version imprimée. Le single source publishing met en œuvre le concept d’hybridation d’Alessandro Ludovico : plutôt que d’éditer plusieurs sources pour autant d’artefacts distincts, des modèles variés sont appliqués à une source unique afin de générer différentes formes. L’hybridation est plus cohérente et plus puissante lorsque tout le contenu d’un projet se trouve au même endroit, réunissant les énergies éditoriales autour d’une même origine, modelée par des gabarits. Il reste alors la question de la circulation de ces formes produites.
L’éditorialisation désigne l’ensemble des dynamiques qui produisent et structurent l’espace numérique. Ces dynamiques sont les interactions des actions individuelles et collectives avec un environnement numérique particulier.
Nous l’avons déjà ditVoir 2.4. L’éditorialisation en jeu, l’éditorialisation est une évolution du concept d’édition dans un environnement numérique, et exprime l’idée selon laquelle l’écriture ou la lecture sont façonnées par les outils et supports que nous utilisons. L’implémentation de l’acte éditorial sémantique dans des chaînes d’édition est une façon de comprendre et de construire cet espace. Le single source publishing est une manifestation de l’éditorialisation, où toutes les forces convergent en une structure horizontale afin de produire des artefacts textuels. La modélisation de notre espace dépend de la manière dont nous concevons et construisons ces processus : méthodes, outils, logiciels libres, approches techniques, etc. L’édition multimodale à partir d’une source unique implique un maniement du texte via différents scénarios, il s’agit d’une action qui correspond au façonnage d’espaces numériques et réels.
Ces trois concepts : l’hybridité des sources d’un projet sous l’effet des multiples formes artefactuelles d’un projet éditorial, l’hybridation des divers artefacts à travers une modélisation éditoriale, ou encore l’éditorialisation, ont en commun la gestion du texte à travers un acte éditorial sémantique. Il est désormais temps de réaliser une étude de cas d’une implémentation spécifique dans le champ de l’édition scientifique, avec l’éditeur de texte sémantique Stylo et ses fonctionnalités d’export.
#4.5. Stylo et son module d’export : fabriquer des livres</>
Commit : 07f3e07
Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-05.md
</>
Commit : 07f3e07Source : https://src.quaternum.net/t/tree/main/item/content/p/04/04-05.md
Quelles sont les modalités d’application des principes du single source publishing en situation réelle telle que l’édition scientifique ? Comment mettre en place un processus d’édition respectant ces principes et quels en sont les agencements le cas échéant ? Cette étude de cas répond à ces deux questions en analysant les fonctionnalités d’export de l’éditeur de texte sémantique Stylo. Comme toutes les études de cas qui ponctuent chacun des chapitres de cette thèse, celle-ci révèle l’implication de l’auteur dans un projet de recherche. Ce dernier est ambitieux et, d’une certaine façon, radical. La coordination des développements de Stylo a structuré le doctorat pendant quatre années, poursuivant un travail engagé puis poursuivi par d’autres. La dimension collective est ici primordiale, tant les idées, les décisions et les réalisations ont fait l’objet d’échanges avec les personnes qui ont contribué au projet — étudiants et étudiantes, chercheurs et chercheuses, éditeurs et éditrices de revues, et ingénieurs. En plus d’expliciter l’usage du format Markdown dans une chaîne d’édition complexe relevant du domaine académique, et de détailler l’implémentation d’un acte d’édition sémantique, cette étude de cas répond à un troisième objectif : montrer comment l’édition et la modélisation d’un processus éditorial sont liées et se répondent. Nous faisons un pas de côté en analysant une fabrique d’articles plutôt que de livres, toutefois l’usage de cet éditeur de texte s’étend aussi à d’autres objets éditoriaux comme nous l’évoquons dans cette analyse.
Plusieurs projets s’inspirent ou intègrent les principes du single source publishing, dans des contextes éditoriaux variés. L’implémentation de ces principes comporte des choix qui sont aussi parfois des compromis, notre objectif ici est donc aussi de nuancer ce qui semble être un horizon presque utopique, tout en proposant des voies alternatives aux initiatives le plus souvent orientées vers XML.
Pour analyser le fonctionnement de ce que nous nommons le module d’export de Stylo, il faut tout d’abord préciser le contexte de la publication scientifique et ses particularités, puis présenter l’éditeur de texte sémantique Stylo et ses origines théoriques et pratiques. Le module d’export de Stylo est analysé en tant que brique logicielle basée sur le convertisseur Pandoc, nous mentionnons ici également ce qui a présidé à son développement initial et ce qui anime ses futures évolutions. Enfin, nous abordons les enjeux techniques et théoriques liés à la production d’articles scientifiques et de livres, nous concentrant sur la modélisation de ces artefacts.
#4.5.1. Le contexte de l’édition savante
L’édition scientifique, ou plus globalement l’éditions savante, est un domaine avec de nombreuses particularités, qui se distingue ainsi fortement de l’édition généraliste — littératures, romans, essais, livres pratiques, etc. Cette distinction se fait sur plusieurs plans, et notamment les types de contenus, leur circulation dans le processus d’édition, les types de formats, ou encore les enjeux de diffusion.
La richesse des contenus des objets éditoriaux savants, d’un point de vue sémantique, rejoint la diversité des formats. En effet, le texte et son matériel critique sont représentés dans des artefacts divers comme des articles, des chapitres, des ouvrages ou des textes d’actes de conférences, répondant à un ensemble d’exigences variées. Les notes de bas de page, les références bibliographiques, les bibliographies, les citations longues, les figures, les index, etc., constituent une diversité et une abondance structurelles que l’imprimé a su intégrer à la page — à un niveau de complexité granulaire encore plus élevé avec les éditions critiques comme nous l’avons vu précédemmentVoir 3.3. Éditer avec le numérique : le cas d’Ekdosis. La transposition en environnement numérique oblige à une modélisation qui se révèle complexe, et qui a donné lieu à des schémas XML dont l’objectif est d’identifier avec justesse les types de fragments qui composent le texte scientifique. Il s’agit là de pouvoir répondre aux nouvelles contraintes de diffusion, où chaque document doit être rendu disponible sur diverses plateformes en ligne, en flux et en version paginée, et parfois aussi au format imprimé.
Le numérique vient ainsi bouleverser les modalités de diffusion de la connaissance, et notamment via les questions de stabilité et de citabilité — comment citer un passage précis d’un article disponible sous forme de page web plutôt qu’imprimée ? (Bleier, 2021) Bleier, R. (2021). How to cite this digital edition? Digital Humanities Quarterly, 015(3). —, sous l’influence des besoins de diffusion en contexte numérique. Pourtant, c’est bien le modèle de l’imprimé qui guide encore les modes de production, dont la page semble être un canon difficilement contournable (Grafton, Allain & al., 2012) Grafton, A., Allain, J. & Loyrette, H. (2012). La page de l’Antiquité à l’ère du numérique: histoire, usages, esthétiques. Hazan / Louvre éditions. . Les outils d’écriture les plus utilisés appuient ce paradigme, les traitements de texte ne permettant pas d’aboutir à un modèle alternatif, notamment basé sur des documents richement structurés et dont la mise en forme est de fait dans les mains de l’éditeur. Même des auteurs et des autrices qui travaillent avec une matière bien moins structurée que celle de l’édition savante le remarquent dès les débuts de l’hégémonie de Microsoft Word (Kirschenbaum, 2016) Kirschenbaum, M. (2016). Track changes: a literary history of word processing. The Belknap Press of Harvard University Press. , et c’est également la critique adressée par Edward Tufte au logiciel Microsoft Powerpoint (Tufte, 2006, p. 156-185) Tufte, E. (2006). Beautiful evidence. Graphics Press. , qui partage le même modèle que Word. Il y a une nécessité à repenser les modalités d’écriture et d’édition, pour inclure les possibilités offertes par le numérique en termes de structuration sémantique, de travail collectif, ou de conversation scientifique (Sauret, 2018) Sauret, N. (2018). Design de la conversation scientifique : naissance d’un format éditorial. Sciences du Design, 8(2). 57–66. https://doi.org/10.3917/sdd.008.0057 .
Parmi d’autres questions, le projet Revue2.0https://revue20.org a répondu à celle-ci : « comment embrasser le numérique pour augmenter la qualité des artefacts éditoriaux et faciliter leur circulation en contexte scientifique ? Autrement dit, comment adapter les chaînes d’édition ? » Ce projet, mené par la Chaire de recherche du Canada sur les écritures numériques de 2018 à 2021L’auteur a participé au projet d’abord en tant que coordinateur d’expérimentations et de prototypes de 2019 à 2020, puis comme coordinateur du projet de 2020 à 2021. Revue2.0 a été financé par le Conseil de recherches en sciences humaines du Canada., a permis de mettre en place différentes méthodes et outils suite à une série d’entretiens, d’ateliers et d’expérimentations — un chapitre de la thèse de Nicolas Sauret est consacré à ce projet (Sauret, 2020, p. 147-240) Sauret, N. (2020). De la revue au collectif : la conversation comme dispositif d’éditorialisation des communautés savantes en lettres et sciences humaines. Thèse de doctorat, Université de Montréal. Consulté à l’adresse https://these.nicolassauret.net . Si la mission de fond était celle d’un accompagnement à la transition numérique, il s’agissait aussi d’expliquer sur un double plan théorique et pratique ce que les structures éditrices de revues savantes pouvaient ou devaient faire du numérique. Le projet Revue2.0 n’est pas le seul à avoir amorcé cette réflexion, nous pouvons notamment citer le rapport Mind the Gap dirigé par John Maxwell, où est réalisée une analyse panoramique des outils et des plateformes de publication open source (Maxwell, 2019) Maxwell, J. (dir.). (2019). Mind the Gap: A Landscape Analysis of Open Source Publishing Tools and Platforms. The MIT Press. Consulté à l’adresse https://mindthegap.pubpub.org/ . Cette recherche rejoint celle de la Chaire de recherche du Canada sur les écritures numériques, et partage la position : toute démarche scientifique doit être basée sur des outils ouverts — voire libres —, et sur des standards. Nous ne citons pas ici d’autres initiatives académiques proche de ces démarches, elles sont néanmoins nombreuses, et s’inscrivent parfois dans le courant des humanités numériques.
L’éditeur de texte sémantique Stylo prend une place centrale au sein du projet de recherche Revue2.0, permettant d’expérimenter la rédaction sémantique, l’évaluation (ouverte, semi-ouverte ou fermée), l’indexation par mots-clés contrôlés, ou encore une chaîne de publication multimodale à partir d’une source unique. Présentons désormais cet éditeur de texte qui fait figure d’exception dans le paysage académique global, d’autant qu’il s’inscrit comme une alternative parmi d’autres démarches de niche — pour ne pas dire marginales.
#4.5.2. Stylo : un éditeur de texte sémantique
Stylo est un éditeur de texte sémantique pour l’édition scientifique en sciences humaines et sociales, conçu par et pour la communauté scientifique. Cet outil d’écriture et d’édition a pour objectif de transformer le flux de travail numérique des revues savantes, notamment en adoptant un mode WYSIWYM et en privilégiant ainsi d’abord le sens du texte avant son rendu graphique. Ses fonctionnalités sont centrées autour du texte et de la dimension sémantique qu’il peut (doit) revêtir dans une perspective de publication académique.
Stylo est un éditeur de texte en ligne conçu spécifiquement pour les sciences humaines et sociales. Il doit permettre de rédiger tout type de textes scientifiques (articles, monographies, thèses, mémoires, ouvrages collectifs, et théoriquement éditions critiques). Visant à combiner les bonnes pratiques de l’édition scientifique et celles de l’édition web […]. Le projet Stylo est né de la volonté de donner aux auteurs la maîtrise de leurs données scientifiques et de l’ensemble de la chaîne éditoriale.
Malgré les efforts de stabilisation de cet outil permise par la très grande infrastructure de recherche Huma-Num, Stylo est un projet de recherche et a vocation à le rester, ce qui signifie qu’il doit être un moyen d’expérimenter des théories et non devenir un produit au service d’une communauté — en tout cas tant qu’il est mené et coordonné par un laboratoire de recherche. Ce positionnement est loin d’être simple, mais il s’inscrit ainsi dans une perspective scientifique revendiquée par l’équipe qui coordonne ce projet (Vitali-Rosati, Sauret & al., 2020) Vitali-Rosati, M., Sauret, N., Fauchié, A. & Mellet, M. (2020). Écrire les SHS en environnement numérique. L’éditeur de texte Stylo. Revue Intelligibilité du Numérique. https://doi.org/10.34745/numerev_1697 — dont l’auteur de cette thèse fait partie.
Stylo est une application en ligne, soit un site web disponible avec une connexion internet et permettant un mode interactif à la façon d’autres éditeurs en ligne. L’avantage est qu’aucune installation de logiciel n’est requise — si ce n’est un navigateur web —, en revanche une connexion internet fiable est nécessaire. Les utilisatrices et les utilisateurs ne sont toutefois pas enfermés avec cet éditeur puisqu’il est possible d’extraire les fichiers sources de l’application, ces fichiers étant des formats standards lisibles et modifiables par d’autres logiciels. L’unité documentaire adoptée est l’article, soit un document comprenant un texte, un matériel critique et des métadonnées descriptives, ce qui n’empêche pas de publier aussi des monographies. En plus d’une interface d’écriture qui n’affiche que le balisage sémantique — choix fort qui correspond à un autre paradigme que celui des traitements de texte —, Stylo permet de prévisualiser une version web du document.
Le fonctionnement de Stylo peut être décrit selon une approche sémantique et plus précisément en explicitant le rôle et les formats (standards et ouverts) des sources nécessaires à l’écriture et à l’édition : Markdown, YAML, BibTeX. La première source est le texte, son format est le langage de balisage léger Markdown — saveur CommonMark/Pandoc, pour faire écho à l’étude de cas précédenteVoir 4.3. Le langage de balisage léger Markdown : entre interopérabilité et compromis —, utilisé ici comme écriture sémantique. Les niveaux de titres, notes, citations, emphases, tableaux et autres listes sont donc exprimés avec les signes typographiques propres à Markdown. Les références bibliographiques sont quant à elles indiquées via une syntaxe propre au convertisseur Pandoc — ce fonctionnement est détaillé par la suite. Pour structurer les métadonnées propres à l’article, Stylo utilise le langage de sérialisation de données YAML, format répandu et souvent utilisé en complément de Markdown. Ici les métadonnées sont stockées dans un fichier distinct du texte, c’est la deuxième source utilisée par l’éditeur. La troisième et dernière source est la bibliographie structurée, au format BibTeX. Chaque référence est décrite dans ce format de sérialisation de données, assez proche de YAML dans l’esprit. Le texte, ses métadonnées et des références bibliographiques structurées, voilà sur quoi se base Stylo. Dit autrement, Stylo n’est qu’une couche interfacielle facilitant l’interaction avec ces fichiers, et proposant par ailleurs des fonctionnalités d’export permises par Pandoc et que nous explorons par la suite.
En tant que projet collectif et scientifique, Stylo est coordonné par un groupe de chercheurs, de chercheuses, d’étudiants et d’étudiantes, en partenariat avec le diffuseur canadien Érudit, la très grande infrastructure de recherche française Huma-Num, la chaîne de publication Métopes à Caen, et des revues partenaires au Canada et en Europe. Il ne s’agit pas tant de financer les développements — majoritairement réalisés par des prestataires —, que de susciter un dialogue autour des pratiques d’écriture et d’édition, autant pour les auteurs et les autrices, les structures d’édition, les diffuseurs ainsi que les organismes de soutien à la recherche.
Avant de présenter et d’analyser le module d’export de Stylo, nous devons préciser que cet éditeur de texte sémantique n’est pas le seul à se baser sur ce trio de formats et sur Pandoc. Une communauté académique assez substantielle utilise ce mode d’écriture pour des productions académiques, nécessitant une littératie numérique relativement importante — utilisation d’un éditeur de texte, d’un terminal et d’un outil capable de générer le format BibTeX. Le logiciel Zettlr a justement été développé comme une surcouche logicielle pour faciliter ces pratiques, proposant des fonctionnalités identiques ou très similaires à celles de Stylo, tout en se démarquant notamment sur le plan de la solution logicielle — plutôt que comme un projet de recherche. L’argumentaire présent sur le site web de Zettlrhttps://zettlr.com adopte les codes des logiciels d’écriture disponibles sur le marché, malgré le fait qu’il soit d’abord un outil pensé par et pour la communauté scientifique, et qu’il soit un logiciel libre (sous licence GNU General Public License v3.0). Zettlr met en avant des arguments pour se positionner face aux traitements de texte ou autres applications d’écriture, constituant ainsi une alternative plus qu’un changement de paradigme profond. Contrairement à Stylo, Zettlr n’a pas encore vocation à intégrer d’autres services développés par la communauté scientifique, pas plus que de se brancher à des flux de diffusion. Il n’en demeure pas moins que Zettlr est une réussite logicielle, et une réponse qui était attendue et qui est désormais adoptée par une large communauté. Un des éléments que Zettlr ne propose qu’en partie, c’est un ensemble de fonctionnalités d’export adaptées à la diffusion scientifique, que nous abordons désormais.
#4.5.3. Les formats du module d’export
Une des spécificités de Stylo est de proposer des modélisations éditoriales répondant aux exigences académiques et permettant ainsi un vaste choix de formats d’export. Si, d’une certaine façon, cet éditeur de texte sémantique n’est qu’une application du format Markdown et du convertisseur Pandoc, cette modélisation constitue une originalité ainsi qu’une plus-value manifeste pour les personnes qui l’utilisent. Ce que nous appelons module d’export est une partie intégrante et néanmoins distincte de l’application d’écriture à proprement parler, comme nous pouvons le voir dans le schéma ci-dessous.
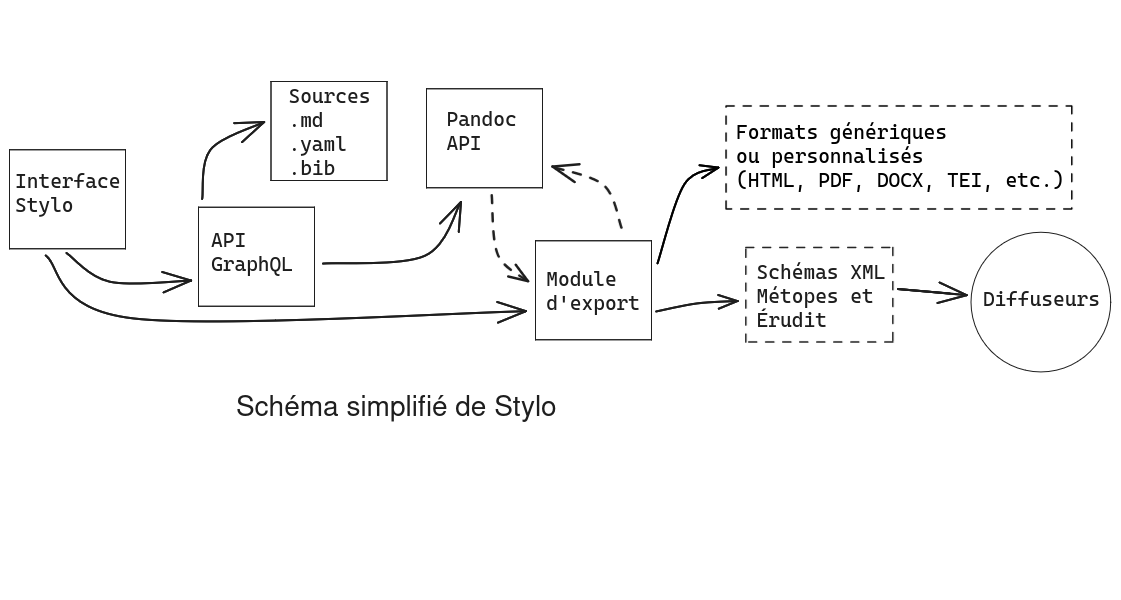
Nous décrivons ici les principes sur lesquels se fonde ce module d’export, ainsi que son fonctionnement (incluant l’usage de Pandoc) en mentionnant son historique ainsi que son développement. Loin d’être un service en plus de l’éditeur de texte, ce module d’export participe à la formalisation de l’acte d’édition sémantique possible avec Stylo.
Avant de lister les formats d’export possibles, il faut préciser que Stylo stocke chacune des données dans une base de données, et expose ces informations via une API (Application Programming Interface pour interface de programmation d’application en français) GraphQL. Cette API permet d’accéder aux données sans passer par l’interface graphique de Stylo, et c’est ce que fait précisément le module d’export ; cette API est aussi conçue pour permettre l’accès aux données à d’autres applications, comme un CMS par exemple. Chaque demande d’export déclenche un processus qui consiste à aller chercher les données dans les champs correspondants de cette base de données, pour ensuite les traiter.
Les formats d’export proposés reflètent les besoins divers en édition scientifique, et notamment la nécessité de disposer d’artefacts structurés, ou prenant en compte les contraintes liées à l’édition sémantique désormais incontournables (Kembellec, 2020) Kembellec, G. (2020). Semantic publishing, la sémantique dans la sémiotique des codes sources d’écrits d’écran scientifiques. Les Enjeux de l'information et de la communication(20/2). 55–74. Consulté à l’adresse https://lesenjeux.univ-grenoble-alpes.fr/2019/dossier/04-semantic-publishing-la-semantique-dans-la-semiotique-des-codes-sources-decrits-decran-scientifiques/ . Le premier format est le format HTML, utile d’abord pour obtenir un rendu graphique et sémantique dans le même environnement que Stylo, le Web, mais aussi pour une intégration manuelle dans des CMS. Le format PDF offre une version paginée, avec un accès au format LaTeX pour des modifications avec le système de composition du même nom. Les formats DOCX et ODT permettent un retour au traitement de texte, en sachant que les exports dans ces formats contiennent une feuille de style par défaut qui facilite l’édition alors en partie structurée dans ces environnements WYSIWYG. Pour une intégration dans un logiciel de publication assistée par ordinateur (comme le logiciel InDesign), l’export au format ICML est proposé. Pour une interopérabilité avec les diffuseurs numériques chargés de rendre disponibles les documents aux communautés scientifiques, plusieurs formats XML sont générés avec trois schémas : TEI (light), Érudit, et TEI Commons Publishing (partagé par Métopes et OpenEdition). Enfin, les fichiers sources eux-mêmes (Markdown, YAML, BibTeX) peuvent être téléchargés. Chaque format prend en compte une série de spécifications qui proviennent des besoins des revues et des diffuseurs, et qui se traduisent par une modélisation que nous détaillons désormais.
#4.4.4. La modélisation dans le processus d’export
Construire une modélisation éditoriale consiste à définir un gabarit pour baliser convenablement les données (texte, informations sémantiques sur le texte, métadonnées, données bibliographiques, style bibliographique, et paramètres indiqués au moment de l’export) pour constituer un format qui répond à des standards précis. Un gabarit est établi pour chaque format d’export. Pandoc — présenté précédemmentVoir 4.3. Le langage de balisage léger Markdown : entre interopérabilité et compromis — est chargé de convertir les fichiers sources selon un modèle, en fonction du format demandé, et selon des paramètres indiqués au moment de l’export — par exemple : faut-il afficher la table des matières ? Pandoc propose son propre langage de template, voici un extrait du gabarit pour l’export au format HTML :
<!--Indexation auteur de l'article--> $if(authors)$ $for(authors)$ <span property="author">$authors.forename$ $authors.surname$</span> $endfor$ $endif$
Dans les quelques lignes de code ci-dessus nous pouvons voir que Pandoc utilise un système de variables, ici authors et forename par exemple, qui correspondent aux clés des champs dans le fichier de métadonnées.
Pandoc a recours à des fonctions issues de la programmation, comme ici une condition avec if (si une condition est remplie alors la partie du template qui suit est activée, jusqu’au endif), ou une boucle avec for (qui permet de récupérer une série de données et d’y appliquer une règle jusqu’à endfor).
Pour le dire autrement, si le document YAML contenant les métadonnées ne comporte aucune information en face de la clé authors alors la ligne qui suit n’est pas appliquée.
Si une donnée est renseignée en face de authors, alors Pandoc applique la suite du template autant de fois qu’il y a de données dans les sous-champs forename et surname.
Si Pandoc propose des modèles par défaut, il est possible de définir entièrement un gabarit, ce qui est le cas pour Stylo.
Les exports XML nécessitent une étape supplémentaire qui consiste à appliquer une feuille de transformations XSL/XSLT sur un contenu structuré en XML ou en HTML.
Nous ne détaillons pas plus ces modèles, ils sont par ailleurs développés sous licence libre et disponible en ligne
(ecrinum,
2023)
ecrinum
(2023).
Stylo export.
Ecrinum. Consulté à l’adresse
https://gitlab.huma-num.fr/ecrinum/stylo/stylo-export
.
Pour appliquer ces différents modèles, Pandoc a été apéifié.
Ce néologisme indique qu’une couche supplémentaire permet de séparer strictement les différentes commandes nécessaires à Pandoc en créant une liste de paramètres que l’API peut prendre en compte.
Ainsi cette API traite une information en entrée, afin de composer en sortie les commandes qui sont ensuite appliquées avec Pandoc.
Stylo est donc constitué de trois éléments : l’éditeur de texte (stylo), le module d’export (stylo-export), et la Pandoc API (pandoc-api).
L’éditeur de texte propose des options d’export aux utilisateurs et aux utilisatrices qui sélectionnent le format et les options souhaitées, ces informations sont transmises au module d’export qui construit les commandes nécessaires à la conversion, grâce à la Pandoc API, sur les sources via l’API GraphQL.
Une fois les commandes de conversion appliquées, les formats produits par le module d’export (toujours avec l’aide de la Pandoc API) sont transmis aux utilisateurs et utilisatrices via l’éditeur de texte — l’interface principale.
Cette décomposition en trois éléments distincts offre un fonctionnement structuré séparant ce qui dépend de l’écriture et de l’édition, et permettant d’adopter un développement dit modulaire qui facilite les évolutions générales et spécifiques.
Cette description technique est essentielle pour comprendre les enjeux théoriques derrière ces programmes. Distinguer les modèles des règles de conversion apporte une meilleure compréhension des mécanismes techniques auxquels les auteurs, les autrices, les éditeurs et les éditrices peuvent contribuer. Avant d’aborder ce point nous devons expliciter l’usage et le rôle du programme Pandoc.
#4.5.5. Pandoc : la raison d’une singularité hégémonique
Quel rôle joue Pandoc dans le développement de ce module d’export et donc dans la modélisation des contenus ? Si Pandoc se définit lui-même comme un outil « universel », il convient d’interroger les contraintes qu’il impose et la raison d’une forme d’hégémonie de ce convertisseur de formats texte.
Nous ne détaillons pas à nouveau le fonctionnement de Pandoc, chose déjà faite dans la section précédenteVoir 4.3. Le langage de balisage léger Markdown : entre interopérabilité et compromis, nous pouvons toutefois rappeler trois caractéristiques de ce logiciel.
Tout d’abord Pandoc convertit des fichiers d’un format de balisage à un autre via un mécanisme complexe reposant sur un analyseur syntaxique, un arbre syntaxique abstrait et des modules d’écriture pour manipuler les données.
Pour simplifier, il applique des règles de conversion permettant de passer d’une expression sémantique balisée à une autre.
Ensuite Pandoc fonctionne en ligne de commandes, dans un terminal, ce qui signifie qu’il ne dispose pas d’interface graphique et qu’il peut être difficile d’accès pour certaines personnes.
Enfin Pandoc adopte un fonctionnement commun à d’autres programmes en ligne de commandes, consistant en des options et des arguments.
La commande pandoc -f markdown -t html fichier-source.md -o fichier-converti.md correspond donc à la conversion du fichier fichier-source.md en un fichier HTML fichier-converti.html.
Pandoc est devenu incontournable dans l’environnement des langages de balisage, la prise en charge de nombreux formats en entrée et en sortie en fait un « couteau suisse » de l’édition. D’autres parseurs existent, souvent limités à un format en entrée et un format en sortie, comme Markdown et HTML — comme nous l’avons vu précédemment avec l’initiative BabelmarkVoir 4.3. Le langage de balisage léger Markdown : entre interopérabilité et compromis qui liste les multiples convertisseurs Markdown et leur saveur associée. Les très nombreuses règles et conditions permettant le passage d’un format à un autre nécessitent des développements longs pour prendre en compte des cas d’usage parfois complexes. Ceci explique pourquoi d’autres initiatives similaires n’ont pas vu le jour, tant les efforts investis dans Pandoc ont déjà été importants. John MacFarlane note lui-même que l’engouement autour de sa création a été rapide, d’abord chez des personnes dans le domaine académique, puis pour plusieurs types d’applications faisant usage de langages de balisage. Notons également que ce convertisseur, aussi utilisé soit-il, est créé, développé et maintenu par un professeur de philosophie — avec quelques personnes qui contribuent désormais également au projet.
L’universalité affichée sur le site web de Pandoc est-elle compatible avec son statut hégémonique ? Un rapide coup d’œil au dépôt du code de Pandochttps://github.com/jgm/pandoc permet de comprendre que les développements et les adaptations se font dans un souci d’interopérabilité, et non pour servir les intérêts d’une entreprise ou d’une personne en particulier. Le développement de Pandoc est clairement tourné vers la communauté, prenant en compte les différents usages liés aux standards dans le domaine de la publication. Toutefois, si le travail collaboratif est permis, le choix du langage de développement de Pandoc limite les contributions directes sur le code. Pandoc est écrit en Haskell, un langage peu répandu avec un haut niveau d’abstraction. Il est en effet basé sur le principe de programmation purement fonctionnelle, dont les opérations reposent uniquement sur l’évaluation de fonctions mathématiques — pour résumer ce principe grossièrement. Ce choix s’explique par l’intérêt du philosophe pour les mathématiques et la logique, Pandoc a d’ailleurs d’abord été un bac à sable pour l’apprentissage de ce langage par John MacFarlane. Le prix de l’implémentation d’un convertisseur d’une telle ampleur — en termes de nombre de langages de balisage pris en charge — est donc désormais une connaissance approfondie de Haskell, ainsi qu’une compréhension de la complexité de la structure actuelle du code. Enfin, la priorité mise sur Markdown, HTML et LaTeX a des effets de bord sur d’autres formats d’export tels que XML-TEI. À titre d’exemple, les données riches des bibliographies ne sont actuellement pas conservées dans l’export au format XML-TEI, comme indiqué dans un tickethttps://github.com/jgm/pandoc/issues/8790 lié au développement du module de Stylo. Il est nécessaire de préciser ces détails pour comprendre l’origine de cet outil de conversion ainsi que son développement continu depuis dix-sept ans, ce qui en fait par ailleurs un exemple de longévité dans le domaine du logiciel libre.
Pour terminer sur cette présentation technique du module d’export de Stylo, soulignons que tous les efforts se concentrent désormais sur une implémentation aussi agnostique que possible de Pandoc.
Cela signifie d’une part que le module pandoc-api est conçu comme une surcouche de Pandoc, des commandes entièrement compatibles avec le convertisseur sont ainsi élaborées, sans traitement supplémentaire ; d’autre part l’usage de templates et de filtres facilite la séparation entre les possibilités du programme et la modélisation elle-même.
Ce choix de développement, réalisé par David Larlet avec la Chaire de recherche du Canada sur les écritures numériques, participe directement à cette modélisation éditoriale, plusieurs des implications épistémologiques induites sont explicitées par la suite.
#4.5.6. Implications épistémologiques de la modélisation
Le module d’export de Stylo est ainsi composé de plusieurs éléments, cette organisation reflète une modélisation éditoriale nécessaire pour les revues et les diffuseurs.
La première version du module d’export a été l’occasion d’un prototypage expérimental sous la forme d’un script BashBash est un interpréteur en ligne de commande, il peut être écrit sous la forme d’un fichier, ce script peut ensuite être exécuté par une console. complexe, cette version démontre l’intérêt mais aussi les limites du bricolage dans le cas de Stylo. Rappelons un moment de l’histoire de cet éditeur de texte sémantique : en 2018 lors de la mise en ligne du prototype développé par Marcello Vitali-Rosati, Servanne Monjour, Nicolas Sauret et Arthur JuchereauNotons également les contributions d’Emmanuel Château-Dutier et de Michael Sinatra., l’export n’est pas encore possible en ligne. Pour pallier le fait que les utilisateurs et les utilisatrices devaient télécharger les sources puis appliquer localement des conversions avec Pandoc (auquel il fallait ajouter l’installation d’une distribution de LaTeX pour la génération des PDF), Marcello Vitali-Rosati écrit rapidement un script BashVoir en ligne : https://framagit.org/stylo-editeur/process/-/blob/book/cgi-bin/exportArticle/exec.cgi destiné à déléguer cette tâche à un serveur. Ce bricolage va pourtant rester la seule manière d’exporter des articles pendant plus de trois ans, avec de nombreuses améliorations apportées au script original. L’usage d’une version précise de Pandoc, ainsi que la lourde installation de LaTeX, obligent à gérer ce module d’export dans un conteneur isolé avec le logiciel Docker. Les contraintes du script Bash et le manque de structure des modèles (templates) ont conduit à une refonte complète de cette partie de Stylo en 2021.
Le module d’export se devait d’être modularisé pour répondre aux exigences épistémologiques de départ, soit le fait de s’extraire d’une confusion entre structure et mise en forme, de transcrire sémantiquement le sens, et enfin de façonner nos propres outils d’écriture et d’édition en tant que communauté scientifique. La phase de prototypage décrite ci-dessus a permis de modéliser ces fonctionnalités d’export avant de trouver et d’implémenter une solution plus cohérente et plus stable. Cette étape de recherche a également accompagné des revues dans leur usage, l’écriture du code étant conjointe à celle des articles. Insistons sur le fait que les développements de Stylo sont continus, et que les phases de création de nouvelles fonctionnalités, d’amélioration ou de résolution de problèmes sont imbriquées dans les étapes d’accompagnement des revues, de formation ou de discussions régulières avec les partenaires.
Stylo et son module d’export impliquent deux modularisations intrinsèquement liées : d’une part les conditions d’application des principes du single source publishing, et d’autre part la constitution d’une chaîne d’édition modulaire. Il s’agit tout d’abord de distinguer les strates d’écriture dans Stylo en quatre couches, nécessaires pour la réalisation d’une publication multimodale à partir d’une source unique : les sources (au nombre de trois) ; les modèles pour les différents types et formats d’export ; les feuilles de styles pour la mise en forme des artefacts, très fortement liées aux modèles ; les programmes, scripts et filtres pour la réalisation des exports. Puisque nous avons déjà détaillé ces programmes ou scripts (éditeur de texte, module d’export et API Pandoc), nous pouvons préciser que Pandoc permet également d’utiliser des filtres pour ajouter des règles de conversion au moment du traitement des données. Cette double modularisation est une volonté de disposer d’une double dimension interopérable : au niveau des contenus et au niveau des opérations de productions des artefacts. Il s’agit de l’intégration d’une sémantique non plus seulement aux textes mais à l’édition elle-même. Ces développements se traduisent néanmoins par des choix et des arbitrages qui relèvent parfois du compromis.
Cette modélisation est le résultat de la prise en compte de plusieurs paramètres : les contraintes de l’édition scientifique telles que présentées plus haut, des besoins propres aux revues académiques en fonction de leur domaine, et de certaines prérogatives des diffuseurs numériques. Les revues ont des spécificités qui dépendent de leur champ, par exemple l’usage récurrent de figures, une mise en page particulière pour les versions numérique et imprimée, ou l’insertion d’extraits de code. Pour que les articles des revues puissent être disponibles sur plusieurs plateformes académiques, les diffuseurs imposent des schémas XML. Les besoins sont globalement similaires d’un diffuseur à un autre, mais leur formalisation diffère, et ainsi plusieurs schémas co-existent : JATS en Amérique du Nord, Érudit au Canada, et TEI Commons Publishing en Europe. Trois exemples de schémas XML permettent la diffusion numérique d’articles scientifiques. Le module d’export intègre le schéma d’Érudit depuis ses débuts, et l’implémentation du schéma TEI Commons Publishing a été mise en production en 2023. Notons que pour permettre une automatisation complète afin de générer les formats pour une diffusion numérique — soit le fait de convertir les sources dans les formats XML idoines sans intervention sur les formats de sortie XML —, des ajustements sont nécessaires : dans la modélisation des données (textes et métadonnées) et dans les pratiques de balisages des personnes écrivant ou éditant avec Stylo. Cela signifie qu’un accompagnement facilite l’utilisation de Stylo, l’éditeur de texte bénéficiant par là même de retours utiles à son amélioration.
Nous n’avons pas abordé la fonctionnalité d’export de livres, mais elle répond aux mêmes exigences académiques, et il s’agit d’une modélisation proche de celle exposée jusqu’ici. Les articles constituent les chapitres ou les parties d’une monographie. La description de cet objet éditorial est néanmoins déléguée dans un espace additionnel — sous la forme d’un fichier YAML supplémentaire —, afin de lever toute ambiguïté sur les niveaux de granularité (chapitres vs livre).
Comment un format s’incarne-t-il dans des pratiques d’édition ? Cette étude de cas, après les développements théoriques qui l’ont précédée, répond à cette question. Les enjeux de la modélisation éditoriale, et plus spécifiquement dans le contexte de la publication scientifique, nous amènent à observer avec une attention accrue l’interconnexion entre des initiatives d’édition et la constitution de chaînes d’édition. Ce que nous analysons ici dans le champ de l’édition académique, notamment en raison de sa position pionnière, est transposable à d’autres domaines des lettres. À quel moment la fabrication de processus d’édition dépend-elle d’actes éditoriaux, et inversement ? Quelles sont les conditions d’émergence des fabriques d’édition ? C’est l’objet du prochain et dernier chapitre.
Références bibliographiques
- Bachimont, B. (2020). Formes, concepts, matières : quels place et rôle pour le numérique et la technique. Dans Philizot, V. & Saint-Loubert Bié, J. (dir.), Technique & design graphique: outils, médias, savoirs. (pp. 204–229). Éditions B42.
- Bachimont, B. (2007). Ingénierie des connaissances et des contenus: le numérique entre ontologies et documents. Hermès Science.
- Baetens, J. (2018). Plain Text: The Poetics of Computation. Leonardo, 51(3). 322–323. https://doi.org/10.1162/leon_r_01627
- Berne, X. (2014). Le ministère du Travail va basculer vers des logiciels de bureautique libres. Consulté à l’adresse https://www.nextinpact.com/article/14311/89239-le-ministere-travail-va-basculer-vers-logiciels-bureautique-libres
- Blanc, J. & Haute, L. (2018). Technologies de l’édition numérique. Sciences du design, 8(2). 11–17. https://doi.org/10.3917/sdd.008.0011
- Bleeker, E., Buitendijk, B. & Dekker, R. (2020). Between Flexibility and Universality: Combining TAGML and XML to Enhance the Modeling of Cultural Heritage Text. Dans Karsdorp, F., McGillivray, B., Nerghes, A. & Wevers, M. (dir.), Proceedings of the Workshop on Computational Humanities Research (CHR 2020). (pp. 340–350). CEUR.
- Bleier, R. (2021). How to cite this digital edition? Digital Humanities Quarterly, 015(3).
- Bortzmeyer, S. (2020). Le protocole Gemini, revenir à du simple et sûr pour distribuer l’information en ligne ? Consulté à l’adresse https://www.bortzmeyer.org/gemini.html
- Bouchardon, S. & Cailleau, I. (2018). Milieu numérique et « lettrés » du numérique. Le français aujourd'hui, 200(1). 117–126. https://doi.org/10.3917/lfa.200.0117
- Boulétreau, V. & Habert, B. (2017). Les formats. Dans Sinatra, M. & Vitali-Rosati, M. (dir.), Pratiques de l’édition numérique. (pp. 145–159). Parcours numériques. Consulté à l’adresse http://www.parcoursnumeriques-pum.ca/les-formats
- Buard, P. (2015). Modélisation des sources anciennes et édition numérique. Thèse de doctorat, Université de Caen. Consulté à l’adresse https://hal.science/tel-01279385
- Burnard, L. (2015). Qu’est-ce que la Text Encoding Initiative ? OpenEdition Press. Consulté à l’adresse http://books.openedition.org/oep/1237
- Clark, D. (2007). Content Management and the Separation of Presentation and Content. Technical Communication Quarterly, 17(1). 35–60. https://doi.org/10.1080/10572250701588624
- Coombs, J., Renear, A. & DeRose, S. (1987). Markup systems and the future of scholarly text processing. Communications of the ACM, 30(11). 933–947. https://doi.org/10.1145/32206.32209
- Crocker, S., Huitema, C. & Postel, J. (1995). Not All RFCs are Standards. Internet Engineering Task Force. https://doi.org/10.17487/RFC1796
- Debouy, E. (2022). Stylo, un éditeur pour les sciences humaines et sociales. RIDE, 15. https://doi.org/10.18716/ride.a.15.3
- DeRose, S. (2004). Markup Overlap: A Review and a Horse.
- DeRose, S., Durand, D., Mylonas, E. & Renear, A. (1990). What is text, really? Journal of Computing in Higher Education, 1(2). 3–26. https://doi.org/10.1007/BF02941632
- Deyzieux, A. (2008). Les grands courants de la bande dessinée. Le français aujourd'hui, 161(2). 59–68. https://doi.org/10.3917/lfa.161.0059
- Dominici, M. (2014). An overview of Pandoc. TUGboat, 35(1). 44–50.
- Ebsi (2018). Terminologie de base en sciences de l’information. École de bibliothéconomie et des sciences de l’information, Université de Montréal.
- ecrinum (2023). Stylo export. Ecrinum. Consulté à l’adresse https://gitlab.huma-num.fr/ecrinum/stylo/stylo-export
- Engst, A. (1992). TidBITS in new format. Consulté à l’adresse https://tidbits.com/1992/01/06/tidbits-in-new-format/
- Epron, B. & Vitali-Rosati, M. (2018). L’édition à l’ère numérique. La Découverte.
- Fagerholm, F. & Münch, J. (2012). Developer experience: Concept and definition. https://doi.org/10.1109/ICSSP.2012.6225984
- Fauchié, A. & Audin, Y. (2023). The Importance of Single Source Publishing in Scientific Publishing. Digital Studies / Le champ numérique. https://doi.org/10.16995/dscn.9655
- Fauchié, A. (2020). Les technologies d’édition numérique sont-elles des documents comme les autres ? Balisages(1). https://doi.org/10.35562/balisages.321
- Fauchié, A. (2018). Markdown comme condition d’une norme de l’écriture numérique. Réél - Virtuel(6). Consulté à l’adresse http://www.reel-virtuel.com/numeros/numero6/sentinelles/markdown-condition-ecriture-numerique
- Fuller, M. (dir.). (2008). Software studies: a lexicon. The MIT Press.
- Genette, G. (2002). Seuils. Éditions du Seuil.
- Goldfarb, C. (1999). The roots of SGML: a personal recollection. Technical Communication, 46(1). 75–83.
- Goldfarb, C. & Rubinsky, Y. (1990). The SGML Handbook. Clarendon Press.
- Grafton, A., Allain, J. & Loyrette, H. (2012). La page de l’Antiquité à l’ère du numérique: histoire, usages, esthétiques. Hazan / Louvre éditions.
- Gruber, J. (2004). Dive Into Markdown. Consulté à l’adresse https://daringfireball.net/2004/03/dive_into_markdown
- Gruber, J. (2004). Markdown Syntax Documentation. Consulté à l’adresse https://daringfireball.net/projects/markdown/syntax#philosophy
- Guay, M. (2020). The story behind Markdown. Consulté à l’adresse https://capiche.com/e/markdown-history
- Hegland, F. (dir.). (2020). The Future of Text (1). Future Text Publishing. https://doi.org/10.48197/fot2020a
- Hyde, A. (2021). Single Source Publishing. Consulté à l’adresse https://coko.foundation/articles/single-source-publishing.html
- IBM (1985). Document Composition Facility: Generalized Markup Language: Implementation Guide. IBM.
- Illich, I. (2014). La convivialité. Éditions Points.
- Jancovic, M., Volmar, A. & Schneider, A. (dir.). (2019). Format Matters Standards, Practices, and Politics in Media Cultures. Meson Press.
- Kalantzis, M. & Cope, B. (2020). Adding sense: context and interest in a grammar of multimodal meaning. Cambridge University Press.
- Kembellec, G. (2020). Semantic publishing, la sémantique dans la sémiotique des codes sources d’écrits d’écran scientifiques. Les Enjeux de l'information et de la communication(20/2). 55–74. Consulté à l’adresse https://lesenjeux.univ-grenoble-alpes.fr/2019/dossier/04-semantic-publishing-la-semantique-dans-la-semiotique-des-codes-sources-decrits-decran-scientifiques/
- Kinross, R. (2009). A4 and Before: Towards a Long History of Paper Sizes. NIAS.
- Kirschenbaum, M. (2016). Track changes: a literary history of word processing. The Belknap Press of Harvard University Press.
- Knuth, D. (1984). Literate Programming. The Computer Journal, 27(2). 97–111. https://doi.org/10.1093/comjnl/27.2.97
- Leonard, S. (2016). Guidance on Markdown: Design Philosophies, Stability Strategies, and Select Registrations. Internet Engineering Task Force. https://doi.org/10.17487/RFC7764
- Littré, É. (1873). Dictionnaire de la langue française / Tome 2. L. Hachette. Consulté à l’adresse https://gallica.bnf.fr/ark:/12148/bpt6k5406698m
- Ludovico, A. & Cramer, F. (2016). Post-digital print: la mutation de l’édition depuis 1894. Éditions B42.
- MacFarlane, J. (2018). Beyond Markdown. Consulté à l’adresse https://johnmacfarlane.net/beyond-markdown.html
- MacFarlane, J. (2021). CommonMark changelog. Consulté à l’adresse https://spec.commonmark.org/changelog.txt
- Marcoux, F. (2014). Le livrel et le format ePub. Dans Sinatra, M. & Vitali-Rosati, M. (dir.), Pratiques de l'édition numérique. (pp. 177–189). Parcours numériques. Consulté à l’adresse http://www.parcoursnumeriques-pum.ca/le-livrel-et-le-format-epub
- Maudet, N. (2022). Une brève histoire des templates, entre autonomisation et contrôle des graphistes amateurs. Revue Design Arts Medias. Consulté à l’adresse https://journal.dampress.org/issues/systemes-logiques-graphies-materialites/une-breve-histoire-des-templates-entre-autonomisation-et-controle-des-graphistes-amateurs
- Maxwell, J. (2022). The Care-ful Reviewer: Peer Review as if People Mattered. Pop! Public. Open. Participatory(4). https://doi.org/10.54590/pop.2022.004
- Maxwell, J. (dir.). (2019). Mind the Gap: A Landscape Analysis of Open Source Publishing Tools and Platforms. The MIT Press. Consulté à l’adresse https://mindthegap.pubpub.org/
- McGann, J. (2004). Marking Texts of Many Dimensions. Dans Schreibman, S., Siemens, R. & Unsworth, J. (dir.), A Companion to Digital Humanities. (pp. 198–217). Blackwell Publishing.
- McGann, J. (2014). A new republic of letters: memory and scholarship in the age of digital reproduction. Harvard University Press.
- McGill, M. (2018). Format. Early American Studies, 16(4). 671–677.
- McLuhan, M. (1968). Pour comprendre les médias: les prolongements technologiques de l’homme. Points [2013].
- Mourat, R. (2018). Le design fantomatique des communautés savantes : enjeux phénoménologiques, sociaux et politiques de trois formats de données en usage dans l’édition scientifique contemporaine. Sciences du Design, no 8(2). 34–44. https://doi.org/10.3917/sdd.008.0034
- Mourat, R. (2020). Le vacillement des formats : matérialité, écriture et enquête : le design des publications en Sciences Humaines et Sociales. Thèse de doctorat, Université Rennes 2. Consulté à l’adresse https://theses.hal.science/tel-03052597
- Mpondo-Dicka, P. (2020). Le Markdown, une praxis énonciative du numérique. Interfaces numériques, 8(2). 304–304. https://doi.org/10.25965/interfaces-numeriques.3915
- Pédauque, R. & Melot, M. (2006). Le document à la lumière du numérique. C&F éditions.
- Perret, A. (2022). Format texte. arthurperret.fr/. Consulté à l’adresse https://www.arthurperret.fr/cours/format-texte.html
- Perret, A. (2020). Histoire typographique de la légèreté. Consulté à l’adresse https://www.arthurperret.fr/histoire-typographique-legerete.html
- Perret, A. (2022). De l’héritage épistémologique de Paul Otlet à une théorie relationnelle de l’organisation des connaissances. Thèse de doctorat, Université Bordeaux Montaigne. Consulté à l’adresse https://these.arthurperret.fr
- Reichenstein, O. (2016). Multichannel Text Processing. Consulté à l’adresse https://ia.net/topics/multichannel-text-processing
- Reid, B. (1980). Scribe: A Document Specification Language and Its Compiler. Thèse de doctorat, ProQuest Dissertations Publishing.
- Sauret, N. (2018). Design de la conversation scientifique : naissance d’un format éditorial. Sciences du Design, 8(2). 57–66. https://doi.org/10.3917/sdd.008.0057
- Sauret, N. (2020). De la revue au collectif : la conversation comme dispositif d’éditorialisation des communautés savantes en lettres et sciences humaines. Thèse de doctorat, Université de Montréal. Consulté à l’adresse https://these.nicolassauret.net
- Tanselle, G. (2000). The Concept of Format. Studies in Bibliography, 53. 67–115.
- TEI Consortium (2023). TEI P5: Guidelines for Electronic Text Encoding and Interchange. https://doi.org/10.5281/ZENODO.3413524
- Tenen, D. (2017). Plain text: the poetics of computation. Stanford University Press.
- The Unicode Consortium (2000). The Unicode standard, version 3.0. Addison-Wesley.
- Thoden, K. (2019). Modeling scholarly publications for sustainable workflows. ELectronic PUBlishing, Academic publishing and digital bibliodiversity. https://doi.org/10.4000/proceedings.elpub.2019.2
- Tufte, E. (2006). Beautiful evidence. Graphics Press.
- Vincent, E. (2020). Métopes, édition et diffusion multisupports : Un exemple de déploiement à l’EHESS. Consulté à l’adresse https://www.annales.org/enjeux-numeriques/2020/resumes/juin/09-en-resum-FR-AN-juin-2020.html
- Vitali-Rosati, M., Sauret, N., Fauchié, A. & Mellet, M. (2020). Écrire les SHS en environnement numérique. L’éditeur de texte Stylo. Revue Intelligibilité du Numérique. https://doi.org/10.34745/numerev_1697
- Vitali-Rosati, M. (2016). Qu’est-ce que l’éditorialisation ? Sens Public(2016). Consulté à l’adresse http://www.sens-public.org/article1184.html
- Volmar, A., Jancovic, M. & Schneider, A. (2019). Format Matters: An Introduction to Format Studies. 7–22. https://doi.org/10.25969/mediarep/13663
- Williams, S., Masutti, C. & Stallman, R. (2013). Richard Stallman et la révolution du logiciel libre: une biographie autorisée (2e éd). Eyrolles.